Привет, коллеги-сисадмины!
Как проверить нагрузку на гипервизор? Это один из ключевых вопросов в работе любого, кто управляет виртуальной инфраструктурой. Чтобы ответить на него прямо: проверка нагрузки на гипервизор — это комплексный процесс, который включает в себя мониторинг основных системных ресурсов (CPU, RAM, I/O диска, сеть) как на уровне самого гипервизора, так и внутри гостевых виртуальных машин, используя комбинацию встроенных инструментов гипервизора, CLI-утилит и централизованных систем мониторинга. Цель — выявить потенциальные узкие места, предотвратить деградацию производительности и обеспечить стабильную работу всей виртуализованной среды.
Почему мониторинг нагрузки на гипервизор критически важен?
Гипервизор — это сердце вашей виртуальной инфраструктуры. Он распределяет физические ресурсы между всеми запущенными виртуальными машинами. Если гипервизор перегружен, это мгновенно сказывается на производительности всех ВМ, что приводит к задержкам, снижению отклика приложений и, в конечном итоге, к недовольству пользователей или даже простоям. Регулярный и глубокий анализ нагрузки позволяет:
- Проактивно выявлять проблемы: Заметить тенденции к росту нагрузки до того, как они станут критическими.
- Оптимизировать ресурсы: Правильно распределять CPU, RAM и I/O между ВМ.
- Планировать емкость: Понимать, сколько еще ВМ можно запустить на текущем оборудовании или когда потребуется апгрейд.
- Устранять неполадки: Быстро локализовать причину деградации производительности.
- Обеспечивать SLA: Гарантировать заявленный уровень сервиса для приложений и пользователей.
Основные метрики для мониторинга
Чтобы получить полную картину, необходимо отслеживать несколько ключевых показателей. Важно понимать, что мы смотрим на использование ресурсов с точки зрения самого гипервизора, а не только изнутри гостевой ОС.
1. Центральный процессор (CPU)
CPU — один из самых частых источников узких мест. На гипервизоре важно отслеживать не только общее использование CPU, но и его распределение.
- Общая загрузка CPU: Процент использования всех доступных ядер/потоков. Высокие значения (например, постоянно выше 80-90%) указывают на нехватку ресурсов.
- CPU Ready Time (для VMware), CPU Wait Time (для KVM/Xen): Это время, которое виртуальная машина ждет, пока гипервизор выделит ей физические ядра. Высокие значения (например, более 5-10% от общего времени ВМ) означают CPU-контенцию, то есть ВМ хочет работать, но нет свободных физических ядер. Это один из самых надежных индикаторов перегрузки CPU на гипервизоре.
- Использование CPU гипервизором: Процент CPU, который сам гипервизор использует для своих нужд (управление ВМ, планировщик, драйверы).
- Использование CPU гостевыми ВМ: Суммарное использование CPU всеми ВМ.
2. Оперативная память (RAM)
Нехватка памяти приводит к своппингу, что резко замедляет систему.
- Общее использование RAM: Сколько физической памяти используется.
- Доступная RAM: Сколько свободной памяти осталось на гипервизоре.
- Memory Ballooning/Swapping: Механизмы, которые гипервизор использует для "отбирания" памяти у ВМ, когда ее не хватает. Активный ballooning или, что хуже, своппинг на диски гипервизора, — четкий сигнал о нехватке памяти.
- Memory Overhead: Память, используемая самим гипервизором для управления каждой ВМ.
3. Дисковый ввод/вывод (I/O)
Производительность дисковой подсистемы часто становится бутылочным горлышком, особенно в средах с множеством ВМ, активно работающих с дисками.
- IOPS (Input/Output Operations Per Second): Количество операций чтения/записи в секунду.
- Пропускная способность (Throughput): Объем данных, передаваемых на диск/с диска в секунду (MB/s).
- Латентность (Latency): Время отклика дисковой подсистемы. Высокая латентность (например, десятки миллисекунд) — главный индикатор проблем с дисками.
- Длина очереди (Queue Depth): Количество ожидающих I/O-операций. Высокое значение указывает на перегрузку.
4. Сеть
Сетевая подсистема может быть перегружена, если ВМ активно обмениваются данными.
Нужен максимальный контроль над производительностью вашего гипервизора?
Для критически важных рабочих нагрузок, где каждая миллисекунда имеет значение, выделенный сервер предлагает непревзойденную производительность и безопасность. Получите полный контроль над вашей инфраструктурой. — from €5.99/mo.
Выбрать сервер →- Пропускная способность: Объем входящего/исходящего трафика (Mbps/Gbps).
- Количество пакетов в секунду (PPS): Может быть важнее пропускной способности для некоторых типов нагрузок.
- Ошибки/отброшенные пакеты: Индикаторы проблем на сетевом уровне.
Инструменты для проверки нагрузки
Для мониторинга можно использовать как встроенные средства гипервизора, так и универсальные утилиты.
1. Инструменты командной строки (CLI)
Эти утилиты незаменимы для быстрой диагностики и глубокого анализа непосредственно на хосте гипервизора (особенно для Linux-основанных, таких как KVM, Proxmox, Xen).
-
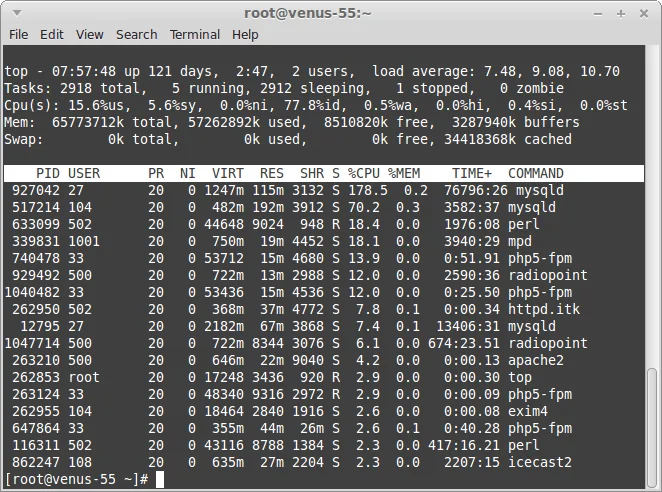
top/htop: Общая картина использования CPU и RAM, список процессов. На гипервизоре покажет использование ресурсов самим гипервизором и процессами, связанными с ВМ (например, qemu-kvm).top -d 2 -
vmstat: Статистика виртуальной памяти, CPU, дискового I/O. Полезно для выявления своппинга и CPU wait.vmstat 2 10Обратите внимание на столбцы
wa(wait I/O) иsi/so(swap in/out). -
iostat: Детальная статистика дискового I/O (IOPS, пропускная способность, латентность).iostat -x -k 2Смотрите на
%util(загрузка диска),await(среднее время ожидания I/O-операции) иsvctm(среднее время обслуживания). -
netstat/ss: Сетевая статистика, открытые соединения, ошибки.netstat -s -t -u -
sar(System Activity Reporter): Мощный инструмент для сбора и анализа истории системных активностей (CPU, память, I/O, сеть). Требует установки пакетаsysstat.sar -u 2 5 # CPU usage sar -r 2 5 # Memory usage sar -b 2 5 # I/O transfer rate -
virsh dominfo <VM_NAME>/virsh cpu-stats <VM_NAME>(для KVM): Позволяет получить информацию о конкретной ВМ, включая использование CPU.
2. Инструменты управления гипервизорами и GUI
Большинство гипервизоров предоставляют свои собственные средства мониторинга, которые дают агрегированную и удобную для восприятия информацию.
-
VMware vCenter/ESXi Host Client: Предоставляет подробные графики производительности для CPU (включая Ready Time), RAM (включая Ballooning), дискового I/O (Latency, IOPS) и сети на уровне хоста и отдельных ВМ. Это основной инструмент для VMware.
Где смотреть: В vCenter Server, выберите хост, затем вкладка "Monitor" -> "Performance" -> "Advanced".
-
Proxmox VE Web Interface: Информативная панель мониторинга с графиками по CPU, RAM, дискам и сети для всего хоста и каждой ВМ. Показывает load average, использование памяти, I/O-статистику.
Где смотреть: В веб-интерфейсе Proxmox, выберите ноду или ВМ, вкладка "Summary" или "Metrics".
-
Microsoft Hyper-V Manager / Windows Admin Center: Позволяет просматривать базовые метрики использования CPU, RAM, дисков для хоста и ВМ. Для более глубокого анализа на Hyper-V хосте можно использовать "Performance Monitor" Windows.
Где смотреть: В Hyper-V Manager, выберите хост, затем "Performance".
-
XenCenter / XCP-ng Center: Предоставляет графики использования ресурсов для хостов и ВМ в среде XenServer/XCP-ng.
3. Централизованные системы мониторинга
Для крупных инфраструктур незаменимы системы, которые собирают метрики со всех гипервизоров и ВМ, агрегируют их и позволяют строить кастомные дашборды и настраивать оповещения.
-
Prometheus + Grafana: Мощная связка. Prometheus собирает метрики (через Node Exporter для хостов, vSphere Exporter для VMware, Telegraf для KVM/Xen) и хранит их. Grafana визуализирует данные, позволяя создавать интерактивные дашборды. Идеально для глубокого анализа и трендов.
Пример запроса PromQL для CPU Ready Time (VMware):
sum by (vmname) (vmware_vm_cpu_ready_average_milliseconds_total[5m]) / 300000 * 100Это покажет средний процент CPU Ready Time за 5 минут.
-
Zabbix: Комплексная система мониторинга, поддерживающая агенты (для хостов) и специальные шаблоны для мониторинга VMware vCenter/ESXi, Hyper-V, KVM. Позволяет настраивать сложные триггеры и оповещения.
-
Nagios / Icinga: Классические системы мониторинга, которые можно настроить для проверки состояния гипервизоров и их ресурсов.
Интерпретация данных и поиск узких мест
Просто видеть цифры недостаточно, нужно уметь их интерпретировать.
-
Установите базовые линии: Понаблюдайте за системой в течение некоторого времени в нормальном режиме работы, чтобы понять, какие значения метрик являются типичными для вашей среды. Любые значительные отклонения от этой базы могут указывать на проблему.
-
Ищите корреляции: Если CPU Ready Time высок, проверьте, не совпадает ли это с пиками I/O или сетевой активности. Возможно, одна ВМ с интенсивной дисковой нагрузкой "отнимает" ресурсы у других, косвенно влияя на CPU.
-
Различайте проблемы гостевой ОС и гипервизора: Если ВМ показывает 100% CPU usage, а гипервизор — низкий CPU Ready Time для этой ВМ, то проблема, скорее всего, внутри гостевой ОС. Если же CPU Ready Time высокий, то гипервизор не успевает выделить ресурсы, и это уже его проблема.
-
Мониторинг ресурсов ВМ: Не забывайте, что поведение гостевых ОС напрямую влияет на гипервизор. ВМ с "голодным" приложением может потреблять избыточные ресурсы, создавая нагрузку на хост. Используйте инструменты внутри ВМ (Task Manager,
top,htop) для выявления виновников. -
Пороговые значения: Определите приемлемые пороговые значения для каждой метрики. Например:
- CPU Ready Time: <5% (иногда до 10% допустимо для коротких пиков).
- Disk Latency: <10-20ms (для критичных приложений <5ms).
- Memory Swapping: 0 (любое активное свопирование — проблема).
Лучшие практики
- Регулярный аудит: Не ждите проблем, чтобы начать мониторинг. Проводите регулярные проверки.
- Автоматизация: Настройте централизованную систему мониторинга с оповещениями, чтобы получать уведомления о проблемах автоматически.
- Документирование: Ведите записи о конфигурации, изменениях и замеченных проблемах.
- Планирование ресурсов: Используйте данные мониторинга для обоснованного планирования расширения инфраструктуры.
- Резервы: Всегда оставляйте некоторый запас ресурсов на гипервизоре для пиковых нагрузок или непредвиденных ситуаций.
Выводы
Проверка нагрузки на гипервизор — это не разовая акция, а непрерывный процесс, требующий внимательности и использования правильных инструментов. Понимание ключевых метрик, умение работать с CLI-утилитами и использование централизованных систем мониторинга позволяют вам не только оперативно реагировать на возникающие проблемы, но и проактивно управлять производительностью вашей виртуальной инфраструктуры. В конечном итоге, это залог стабильности, эффективности и отказоустойчивости ваших сервисов. Держите руку на пульсе, коллеги, и ваша инфраструктура скажет вам "спасибо"!
Оптимизируйте нагрузку гипервизора с гибкими облачными решениями
Масштабируйте ресурсы по требованию, чтобы легко справляться с пиковыми нагрузками и обеспечивать стабильную производительность. Начните работу с нашими облачными инстансами сегодня.
Начать в облаке →