
Hybrid Infrastructure Management: Kubernetes on Bare Metal and in the Cloud with Rancher
TL;DR
- Hybrid Kubernetes with Rancher is a strategic choice for 2026 for companies aiming for a balance between performance, cost, security, and flexibility.
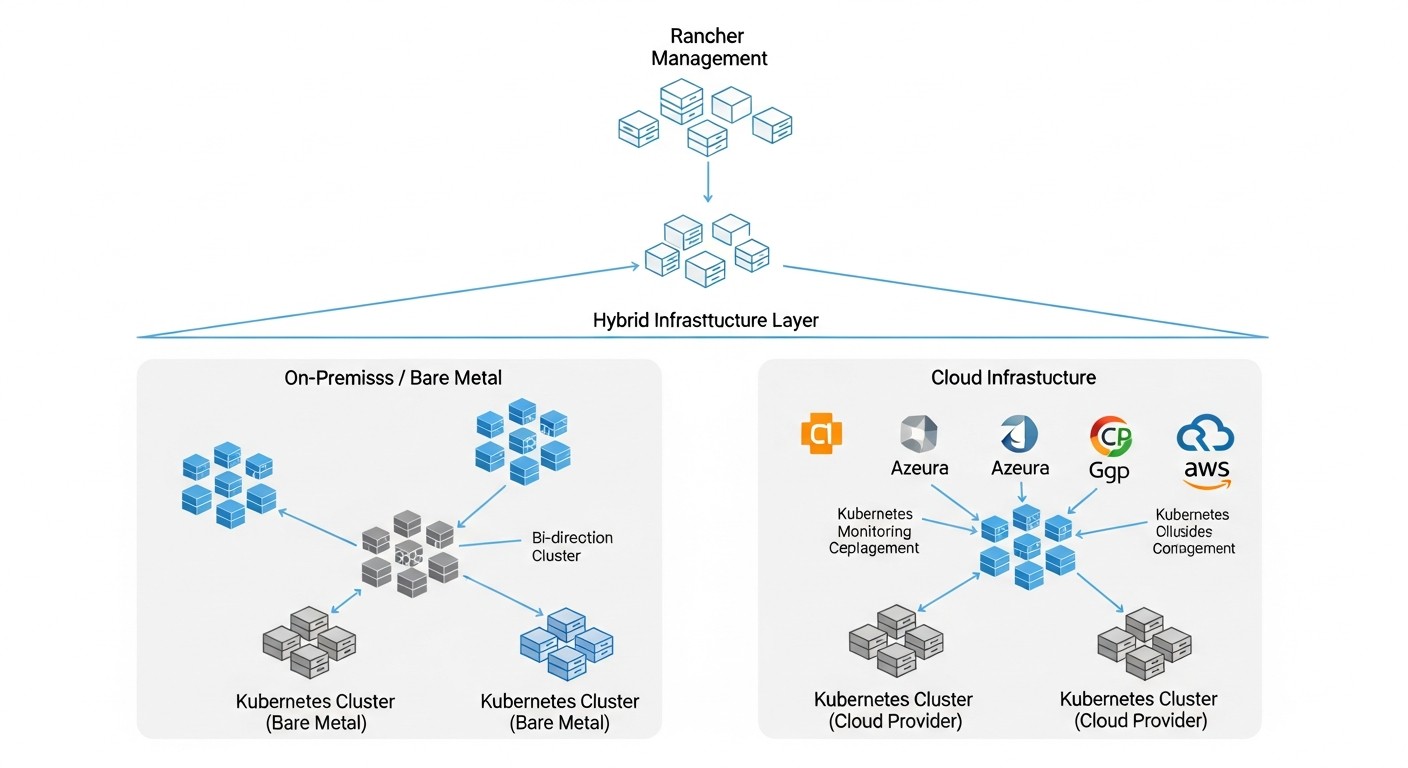
- Bare metal offers unparalleled performance and control, while the cloud provides elasticity and manageability; Rancher unifies these into a single control plane.
- Key success factors include a well-thought-out network architecture, a unified identity and access management strategy, and a comprehensive approach to monitoring and disaster recovery.
- Avoid common mistakes: underestimating network and storage complexity, lacking a clear DR plan, and ignoring hidden data transfer costs.
- Rancher significantly simplifies the deployment, management, and security of Kubernetes clusters both on-premises and with various cloud providers, reducing operational overhead.
- Cost savings are achieved by optimally distributing workloads: resource-intensive and data-sensitive applications on bare metal, scalable and temporary ones in the cloud.
- Real-world case studies show that hybrid solutions enable compliance with strict regulatory requirements, cost optimization, and high service availability.
Introduction
By 2026, the concept of hybrid infrastructure has ceased to be a niche solution and has transformed into a dominant approach for most large and medium-sized enterprises, as well as ambitious startups. In the constantly changing IT landscape, where time-to-market, cost optimization, and compliance with regulatory requirements are critically important, pure cloud or exclusively on-premises strategies often prove insufficient. A hybrid approach, especially using Kubernetes as a universal orchestration platform and Rancher as a unified cluster manager, offers a powerful solution to these challenges.
Why is this topic so important right now? Firstly, the economic instability of recent years forces companies to carefully review their IT budgets, and cloud expenses, which grow rapidly with scale, often become a subject of close scrutiny. Bare metal, with its predictable capital expenditures and no monthly resource fees, is regaining relevance for stable, resource-intensive workloads. Secondly, tightening data protection legislation (e.g., GDPR 2.0, local data sovereignty requirements) compels many organizations to keep sensitive information on their own servers, while using the cloud for less critical or public services. Thirdly, technological advancements in networking (5G, edge computing) and management platforms like Rancher have significantly simplified the integration and management of heterogeneous environments, making hybrid scenarios not only possible but also practical.
This article aims to address a number of key problems faced by modern engineers and executives:
- Management Complexity: How to effectively manage multiple Kubernetes clusters deployed in different environments (on-premises and across multiple clouds)?
- Cost Optimization: How to reduce operational costs by leveraging the benefits of bare metal for stable workloads and the cloud for peak loads?
- Security and Compliance: How to ensure unified security policies and compliance with regulatory requirements in a distributed infrastructure?
- Performance: How to achieve maximum performance for mission-critical applications while maintaining cloud flexibility?
- Migration and Modernization: How to smoothly transition existing applications to a container platform in a hybrid environment?
This guide is written for a broad audience of technical specialists and managers who make strategic infrastructure decisions: DevOps engineers striving for automation and process unification; Backend developers (Python, Node.js, Go, PHP) who need a reliable and scalable platform for their applications; SaaS project founders seeking an optimal balance between cost and flexibility; system administrators responsible for system stability and security; and, of course, CTOs of startups who need to build a resilient and competitive infrastructure from scratch.
We will delve into details, provide specific examples, calculations, and practical recommendations based on real-world experience implementing hybrid Kubernetes solutions with Rancher. Our goal is to give you a comprehensive resource for making informed decisions and successfully implementing your hybrid strategy.
Key Criteria and Factors
When planning and implementing a hybrid Kubernetes infrastructure, it is necessary to consider many factors that collectively determine the success and effectiveness of the solution. Each of these criteria has its own weight and can be prioritized depending on the business specifics, the nature of workloads, and the company's strategic goals. A detailed analysis of each will allow for informed decision-making.
1. Total Cost of Ownership (TCO) and Economic Efficiency
Why it's important: TCO goes far beyond direct costs for hardware or cloud subscriptions. It includes capital expenditures (CapEx) for servers, network equipment, storage, as well as operational expenditures (OpEx) — electricity, cooling, maintenance, software licenses, personnel salaries, traffic costs, and hidden costs such as downtime or training. A proper TCO assessment allows choosing the most economically viable strategy for the long term.
How to evaluate: Conduct a detailed analysis of all expense items over 3-5 years. For bare metal, consider equipment depreciation, data center costs, and personnel. For the cloud, consider monthly payments for resources (vCPU, RAM, storage), network traffic (especially egress), managed services, and potential discounts for reservations (Reserved Instances, Savings Plans). It is important to note that for stable, high-load applications, bare metal is often cheaper in the long run, while the cloud wins at startup and for unpredictable loads.
2. Performance and Latency
Why it's important: Some applications, such as high-frequency trading, edge IoT analytics, game servers, or write-intensive databases, are critically dependent on minimal latency and maximum throughput. Bare metal often wins here, providing direct access to hardware without the overhead of virtualization and cloud network abstractions.
How to evaluate: Measure network latency (RTT) between components, disk I/O throughput (IOPS, throughput), and CPU performance. For bare metal, these will be real hardware metrics. For the cloud, these are the characteristics of the instances and storage types you choose. In a hybrid environment, latency between on-premises and cloud segments is critical and can be reduced through direct connections (Direct Connect, ExpressRoute).
3. Security and Regulatory Compliance
Why it's important: Data protection and compliance with legislation (GDPR, HIPAA, PCI DSS, etc.) are not just "good practice" but a mandatory condition for doing business, especially in sectors such as finance, healthcare, or government services. Hosting sensitive data on your own servers gives full control over physical security and access, which simplifies auditing.
How to evaluate: Audit current and future regulatory requirements. Assess where data should be stored and processed. In the cloud, you share security responsibility (Shared Responsibility Model), which requires careful configuration. On bare metal, all responsibility lies with you, but so does full control. Rancher helps unify security policies and access management (RBAC) across all clusters, regardless of their location.
4. Scalability and Flexibility
Why it's important: The ability of infrastructure to quickly adapt to changing loads is fundamental for successful product development. The cloud offers virtually limitless elasticity, allowing resources to be scaled up or down instantly. Bare metal requires upfront planning and equipment procurement but provides stable and predictable performance for baseline loads.
How to evaluate: Determine peak and baseline loads. Estimate the time required to add new resources in each environment. A hybrid approach allows using bare metal for "constant" load and "bursting" peak requests into the cloud, ensuring optimal resource utilization and cost minimization.
5. Management Overhead and Operational Complexity
Why it's important: Managing distributed infrastructure can be extremely complex without the right tools. High operational costs can negate any savings on hardware or cloud resources. Rancher plays a key role here by providing a single control plane for all Kubernetes clusters.
How to evaluate: Assess the required personnel, their qualifications, training costs, and the complexity of deployment, monitoring, updating, and troubleshooting processes. Automation and unification tools, such as Rancher, significantly reduce this complexity, allowing dozens of clusters to be managed with fewer resources.
6. Vendor Lock-in Risk
Why it's important: Complete reliance on a single cloud provider can lead to pricing issues, limited technology choices, and migration difficulties. A hybrid strategy, especially using Kubernetes, which is an open standard, reduces this risk by allowing workloads to be easily moved between different environments.
How to evaluate: Analyze the cloud services used: how proprietary are they? What effort would be required to migrate to another provider or to bare metal? Kubernetes and Rancher promote standardization, making applications more portable. This gives you leverage in negotiations with vendors and strategic freedom.
7. Data Gravity
Why it's important: Large volumes of data have "gravity" — they are difficult and expensive to move. Applications that intensively work with large databases or storage are often best located close to this data. If data is on bare metal, then applications working with it should logically be placed there to minimize latency and traffic costs.
How to evaluate: Determine the volume and intensity of data exchange between components of your system. Egress traffic costs from the cloud can be significant. Placing databases and analytical systems on-premises or on dedicated servers in the cloud, and frontends and API gateways in more elastic cloud clusters, can be an optimal strategy.
8. Disaster Recovery (DR) and High Availability (HA)
Why it's important: Infrastructure fault tolerance is a critically important factor for any modern business. A hybrid environment offers unique opportunities for building robust DR strategies, allowing risks to be distributed across different locations and providers.
How to evaluate: Define target RTO (Recovery Time Objective) and RPO (Recovery Point Objective) for your applications. Consider scenarios of data center or cloud region failure. A hybrid strategy allows having a backup cluster in the cloud for on-premises applications or vice versa, ensuring rapid activation in case of failure. Rancher simplifies the management of such distributed clusters, allowing centralized management of their configuration and deployment.
Considering these factors at the design stage will allow building not just a functional, but also an efficient, cost-effective, and resilient hybrid infrastructure based on Kubernetes and Rancher.
Comparison Table
For clarity and informed decision-making, let's present a comparative table of the main approaches to Kubernetes deployment, taking into account the hybrid strategy and the role of Rancher. The data is relevant for 2026 forecasts, reflecting trends in pricing, performance, and operational models.
| Criterion | Bare Metal (Self-managed K8s) | Bare Metal (K8s with Rancher) | Public Cloud (EKS/AKS/GKE) | Hybrid (K8s with Rancher) |
|---|---|---|---|---|
| Cost (3-year TCO, $K) | High CapEx (~$100-500K for 10 servers), low OpEx ($5-15K/month) | High CapEx (~$100-500K for 10 servers), medium OpEx ($8-20K/month, including Rancher support) | Low CapEx ($0), high OpEx ($15-50K/month for equivalent of 10 servers) | Balanced CapEx/OpEx ($50-200K CapEx, $10-30K/month OpEx) |
| CPU/RAM Performance | ~95-98% of physical hardware. Direct access to resources. | ~95-98% of physical hardware. Minor overhead from Rancher agents. | ~70-90% of physical hardware (due to virtualization). Depends on instance type. | Bare Metal part: 95-98%. Cloud part: 70-90%. Optimal for different workloads. |
| Network Latency (within cluster) | <1 ms (physical network) | <1 ms (physical network) | ~1-5 ms (cloud virtual network) | Bare Metal: <1 ms. Cloud: 1-5 ms. Inter-cluster: 10-50 ms (with Direct Connect <5 ms). |
| Scalability | Manual, slow (procurement, installation). Up to several weeks. | Semi-automatic with Rancher, but limited by physical resources. Days/weeks. | Automatic, fast (several minutes) with Cluster Autoscaler. Virtually limitless. | Flexible: Bare Metal for base, Cloud for peaks (minutes). Optimal balance. |
| Security and Control | Full control over the entire stack, from hardware to software. High level of security. | Full control + unified security management via Rancher. | Shared responsibility model. High provider security, but less control. | High control for sensitive data (on-prem), shared responsibility model for cloud. |
| Management Complexity | Very high (manual deployment, updates, monitoring). Requires deep knowledge. | Medium-high (Rancher significantly simplifies K8s, but bare metal requires administration). | Medium (managed services, but provider-specific nuances). | High, but reduced by Rancher, which unifies management. Requires expertise. |
| Compliance | Full control over data and infrastructure. Easier to pass audits. | Full control + unified policies via Rancher. | Depends on provider and region. Shared responsibility. | Optimal: sensitive data on-prem, rest in cloud with regional compliance. |
| Vendor Lock-in Risk | Low (open standard K8s). | Low (Rancher is open, but there's a tie to its management ecosystem). | High (deep integration with provider's cloud services). | Low (ability to move workloads, use different providers). |
Note: The figures in the table are estimates and may vary depending on the specific implementation, project scale, region, and team qualifications. Price ranges are for a medium-sized enterprise operating the equivalent of 10-20 physical servers.
Detailed Review of Each Item/Option
Understanding the strengths and weaknesses of each Kubernetes deployment approach is critical for choosing the optimal strategy. Let's examine each option in detail, focusing on its applicability and features in the context of 2026.
1. Kubernetes on Bare Metal (Self-managed)
This approach involves deploying Kubernetes directly on physical servers without an intermediate virtualization layer or management platforms like Rancher. You are fully responsible for all aspects: from OS installation and network configuration to deploying Kubernetes components (kubeadm, kops, kubespray) and their subsequent maintenance.
Pros:
- Maximum Performance: Direct access to hardware resources ensures minimal overhead and highest performance for CPU, RAM, disks, and network. This is critical for high-performance computing (HPC), I/O-intensive databases, AI/ML models, and low-latency network services.
- Full Control and Customization: You control every aspect of the infrastructure, allowing fine-tuning of the system to unique requirements. This is important for specific hardware configurations, specialized network solutions, or particular security requirements.
- Economy of Scale: For very large, stable clusters (hundreds of nodes), in the long run, bare metal CapEx can be significantly lower than cloud OpEx, especially if you have your own data center or co-location.
- Vendor Independence: No lock-in to a cloud provider or management platform.
Cons:
- High Complexity and Operational Overhead: Deployment, updates, monitoring, and troubleshooting require deep knowledge of Kubernetes, networking, and system administration. This significantly increases OpEx due to highly skilled personnel.
- Long Deployment Time: Procurement, delivery, installation, and configuration of hardware can take weeks or months. Scaling also does not happen instantly.
- Lack of Elasticity: Resources are limited by existing hardware. Bursting to the cloud is not possible without a hybrid strategy.
- HA and DR Challenges: Building a fault-tolerant architecture and disaster recovery plan falls entirely on your team.
Who it's for:
Large enterprises with their own data centers that require maximum performance and control, and have a staff of highly skilled engineers. Companies working with very sensitive data where full control over physical infrastructure is required. Projects with predictable but very high loads where cloud costs become prohibitive.
2. Kubernetes on Bare Metal with Rancher
This option leverages the benefits of bare metal while adding the power and convenience of Rancher for managing the Kubernetes cluster lifecycle. Rancher allows deploying, updating, and managing multiple Kubernetes clusters (RKE, K3s) on physical servers from a single pane of glass.
Pros:
- Simplified Management: Rancher significantly reduces operational complexity by automating many routine tasks for cluster deployment and updates. A single UI/API for all clusters.
- Operational Consistency: Rancher provides a unified approach to cluster management, regardless of their location. This unifies security, monitoring, and application deployment policies.
- Leveraging Bare Metal Advantages: High performance and full control over hardware are maintained.
- Ecosystem Integration: Rancher provides access to application catalogs, monitoring tools (Prometheus/Grafana), logging (Fluentd/Loki), CI/CD (ArgoCD/Flux), and other components, simplifying the construction of a comprehensive solution.
- Foundation for Hybrid: Rancher is inherently designed for managing multi-cluster and multi-cloud environments, making it an ideal choice for a hybrid strategy.
Cons:
- Rancher Learning Curve: While Rancher simplifies K8s, the platform itself has its own learning curve.
- Rancher Overhead: Minor overhead for Rancher agents and the management server.
- Bare Metal Administration Still Required: You are still responsible for the physical hardware, its maintenance, power, cooling, and the base OS.
- Limited Elasticity: Scaling a bare metal cluster is still limited by physical resources and the time it takes to acquire/install them.
Who it's for:
Companies that want to use bare metal for performance and control but also minimize the operational overhead of Kubernetes administration. Ideal for the foundation of a hybrid infrastructure where centralized management of heterogeneous clusters is required. SaaS projects that have reached a scale where cloud costs become excessive but are not ready for full manual K8s orchestration.
3. Kubernetes in Public Cloud (EKS/AKS/GKE)
This is the most popular approach for many startups and companies that value deployment speed, elasticity, and managed services. Cloud providers offer fully managed Kubernetes services (Amazon EKS, Azure AKS, Google GKE), relieving you of most of the burden of control plane management.
Pros:
- High Elasticity and Scalability: Instant scaling up and down, automatic node addition/removal. Pay-as-you-go.
- Minimal Operational Overhead for K8s: The provider manages master nodes, their updates, security, and availability. You focus on applications.
- Wide Range of Managed Services: Easy integration with databases, message queues, load balancers, serverless functions, and other cloud services.
- Global Coverage and DR: Ability to deploy in multiple regions and availability zones for high availability and disaster recovery.
- Quick Start: Cluster deployment takes minutes.
Cons:
- High OpEx at Scale: As resources and network traffic (especially egress) grow, cloud costs can become very significant and unpredictable.
- Vendor Lock-in: Deep integration with proprietary cloud services makes migration to another provider or to bare metal difficult.
- Limited Control: Less control over the underlying infrastructure, network settings, and some security aspects.
- Performance/Latency Issues: Virtualization and network abstraction overhead can lead to higher latency and lower performance compared to bare metal.
- Compliance Challenges: The shared responsibility model requires careful auditing and configuration to meet strict regulatory standards.
Who it's for:
Startups that are growing rapidly and need maximum flexibility. Companies with unpredictable or highly fluctuating loads. Projects where time-to-market is more important than absolute minimization of infrastructure costs. Teams that want to minimize administrative infrastructure overhead and focus on development.
4. Hybrid Kubernetes with Rancher
This is a combination of bare metal and cloud Kubernetes clusters, managed from a single Rancher control plane. This approach allows leveraging the advantages of each environment while minimizing their disadvantages.
Pros:
- Cost Optimization: Placing stable, resource-intensive workloads on bare metal (low OpEx in the long run) and using the cloud for elastic, peak loads or temporary environments (Dev/Test).
- Maximum Flexibility and Scalability: Combining the predictable performance of bare metal with the unlimited elasticity of the cloud. Ability to "burst" workloads into the cloud.
- Enhanced Security and Compliance: Sensitive data and mission-critical applications can remain on bare metal under full control, while public and less critical services are hosted in the cloud. Rancher ensures unified security policies.
- Improved Disaster Recovery: Ability to build fault-tolerant architectures where one segment of the infrastructure serves as a backup for another (e.g., on-premises cluster as DR for a cloud cluster and vice versa).
- Reduced Vendor Lock-in: Ability to use multiple cloud providers (multi-cloud strategy) and bare metal, which provides greater choice and application portability.
- Unified Management: Rancher provides a single interface for managing all clusters, simplifying operations, monitoring, and application deployment.
Cons:
- High Initial Complexity: Designing and deploying a hybrid infrastructure requires significant expertise in networking, security, data storage, and, of course, Kubernetes and Rancher.
- Network Integration Challenges: Ensuring seamless and secure communication between on-premises and cloud clusters can be a non-trivial task (VPN, Direct Connect, SD-WAN).
- Data Management: Strategies for synchronizing, replicating, and accessing data across different environments require careful planning.
- Potential Hidden Costs: Costs for egress traffic, direct connections, specialized equipment.
Who it's for:
Practically any company that strives for an optimal balance between cost, performance, security, and flexibility. Particularly relevant for large enterprises that need to modernize outdated on-premises infrastructure, comply with strict regulatory requirements, and for SaaS providers who want to optimize their cloud costs while maintaining elasticity. An ideal choice for those who already have significant investments in bare metal and want to expand their capabilities with the cloud, or vice versa, who want to bring some workloads back from the cloud to their own servers.
The choice of a specific option or combination thereof should always be based on a deep analysis of current needs, future development plans, and available resources. A hybrid strategy with Rancher provides the most complete set of tools to adapt to these requirements.
Practical Tips and Recommendations
Successful implementation of a hybrid Kubernetes infrastructure with Rancher requires not only understanding the theory but also a deep dive into practical aspects. Here are key recommendations and step-by-step instructions based on real-world experience.
1. Network Architecture Design
The network is the circulatory system of your hybrid infrastructure. Its proper design is critical for performance, security, and availability.
Step-by-step instructions:
- IP Planning: Allocate non-overlapping IP address ranges for each on-premises and cloud cluster, as well as for connections between them. Use RFC1918 for private networks.
- On-premises and Cloud Connection:
- VPN (IPsec/OpenVPN/WireGuard): For initial setup or small traffic volumes. Easy to configure, but has limitations on bandwidth and latency.
- Direct Connect (AWS)/ExpressRoute (Azure)/Cloud Interconnect (GCP): For high-performance, low-latency, and stable connections. These are dedicated lines providing predictable performance but requiring significant investment.
- SD-WAN: A modern solution for managing traffic across various channels, optimizing routing, and ensuring security.
- Network Plugins (CNI) for Kubernetes:
- Calico/Cilium: Excellent choice for hybrid environments as they support Network Policies, provide high performance, and can operate in different modes (IP-in-IP, BGP). Calico also supports BGP integration for bare metal clusters.
- Flannel: Simpler to configure but less functional and performant. Good for simple scenarios.
- DNS Strategy: Implement a unified DNS strategy for name resolution between on-premises and cloud clusters. Use CoreDNS in Kubernetes and configure conditional forwarders to on-premises DNS servers for internal domains and vice versa.
- Load Balancing:
- Bare Metal: Use MetalLB to provide LoadBalancer Service. It allocates IP addresses from a pool and announces them via BGP or ARP.
- Cloud: Use native cloud load balancers (AWS ELB/ALB, Azure Load Balancer, GCP GCLB).
- Ingress Controllers: NGINX Ingress Controller, Traefik, Istio Ingress Gateway for routing HTTP/S traffic.
# Example MetalLB configuration (bare metal)
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: bare-metal-lb-pool
spec:
addresses:
- 192.168.100.200-192.168.100.250
---
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: bare-metal-bgp-advertisement
spec:
ipAddressPools:
- bare-metal-lb-pool
2. Data Storage Strategy
Data is the heart of your applications. Choosing the right storage strategy in a hybrid environment is critically important.
Step-by-step instructions:
- CSI (Container Storage Interface): Use CSI drivers to integrate Kubernetes with various storage types.
- On-premises Storage:
- Rook (Ceph): Distributed storage built on local server disks. Provides block, file, and object storage, high availability, and scalability.
- Longhorn: Lightweight distributed block storage, also built on local disks, managed from Kubernetes. Well-suited for small to medium clusters.
- External Storage (NFS/iSCSI): Integration with existing NAS/SAN systems via appropriate CSI drivers.
- Cloud Storage:
- Managed Disks: AWS EBS, Azure Disks, GCP Persistent Disks for block storage attached to a specific VM.
- Managed File Storage: AWS EFS, Azure Files, GCP Filestore for shared file access.
- Object Storage: AWS S3, Azure Blob Storage, GCP Cloud Storage for object storage (often used for backups, static files).
- Replication and Backup Strategy: For mission-critical data, consider replication between on-premises and cloud (e.g., database synchronization, Ceph replication between clusters). Use Velero for backing up and restoring Kubernetes resources and Persistent Volumes.
# Example PersistentVolumeClaim for Longhorn
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-app-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 10Gi
3. Identity and Access Management (IAM)
A unified authentication and authorization system simplifies user management and ensures security.
Step-by-step instructions:
- Centralized Identity Provider: Integrate Rancher with corporate LDAP/AD, Okta, Auth0, or other SSO solutions. This will allow users to log into Rancher using their corporate accounts.
- RBAC in Kubernetes: Configure Role-Based Access Control (RBAC) in each cluster, as well as global roles in Rancher. Define who has access to clusters, namespaces, and specific resources.
- Principle of Least Privilege: Grant users and applications only the permissions necessary to perform their tasks.
4. CI/CD for Hybrid Environment
Automating application deployment in a hybrid environment requires a well-designed CI/CD pipeline.
Step-by-step instructions:
- GitOps: Use Git as the single source of truth for your cluster and application configurations. Tools like ArgoCD or Flux will synchronize cluster state with the Git repository.
- Multi-cluster Deployment: Configure pipelines to deploy applications to specific on-premises or cloud clusters, or even to multiple clusters simultaneously. Rancher Fleet can be used for centralized deployment and management of applications across a large number of clusters.
- Secrets: Use HashiCorp Vault, External Secrets Operator, or cloud secret managers for secure storage and access to sensitive data.
# Example ArgoCD Application for deployment in a hybrid cluster
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-hybrid-app
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/my-org/my-app-configs.git
targetRevision: HEAD
path: k8s/production/hybrid-cluster
destination:
server: https://kubernetes.default.svc # Or your Rancher cluster URL
namespace: my-app
syncPolicy:
automated:
prune: true
selfHeal: true
5. Monitoring and Logging
A unified monitoring and logging system is critical for the health and debugging of a hybrid infrastructure.
Step-by-step instructions:
- Monitoring: Deploy Prometheus and Grafana in each cluster or centrally. Rancher includes built-in integration with Prometheus and Grafana, simplifying their setup. Collect metrics from nodes, pods, containers, as well as network and disk metrics.
- Logging: Use a centralized logging system such as ELK Stack (Elasticsearch, Logstash, Kibana) or Loki with Grafana. Configure Fluentd/Fluent Bit in each cluster to collect logs and send them to central storage.
- Alerts: Configure Alertmanager (part of Prometheus) to send notifications to Slack, PagerDuty, email when problems arise.
6. Disaster Recovery (DR) Strategy
It is essential to have a clear action plan in case of failures.
Step-by-step instructions:
- Define RTO/RPO: For each application, determine the acceptable recovery time (RTO) and acceptable data loss (RPO).
- Backup and Restore: Use Velero for backing up and restoring Kubernetes resources (Deployments, Services, ConfigMaps) and Persistent Volumes. Velero can save backups to object storage (S3-compatible or cloud-based).
- Geographic Distribution: Deploy clusters in different geographic locations (on-premises data center, different cloud regions) to protect against regional failures.
- DR Testing: Regularly test your DR plan by simulating failures and verifying recovery procedures. This is the only way to ensure its functionality.
# Example cluster backup with Velero
velero backup create my-cluster-backup --include-namespaces my-app-namespace --wait
# Example cluster restore with Velero
velero restore create --from-backup my-cluster-backup --wait
7. Kubernetes Version Management and Updates
Updating Kubernetes can be complex, but Rancher significantly simplifies this process.
Step-by-step instructions:
- Planning: Keep track of Kubernetes version lifecycles. Plan updates in advance, considering application compatibility.
- Rancher for Updates: Rancher allows updating Kubernetes versions for managed clusters via UI or API. This significantly simplifies the process by automating many steps.
- Staged Updates: Update clusters not all at once, but in stages: first dev/test, then staging, and only then production.
- Testing: After each update, conduct thorough regression testing of applications.
By applying these practical tips, you can build a reliable, efficient, and easily manageable hybrid infrastructure based on Kubernetes and Rancher, ready for the challenges of 2026 and beyond.
Common Mistakes
Implementing a hybrid infrastructure is a complex project, and it's easy to make mistakes along the way that can lead to significant costs, downtime, or security issues. Learning about these common mistakes and knowing how to prevent them is key to successful implementation.
1. Underestimating Network Integration Complexity
Mistake: Many engineers underestimate how complex it can be to set up a seamless and secure network between on-premises and cloud clusters. Problems with IP planning, routing, DNS resolution, and bandwidth often surface in later stages, leading to delays and rework.
How to avoid:
- Start with detailed IP planning, ensuring no overlapping ranges.
- Invest in reliable inter-network connectivity (Direct Connect, ExpressRoute) for mission-critical workloads. For less demanding ones, you can start with VPN.
- Use advanced CNI plugins like Calico or Cilium, which support network policies and BGP.
- Implement a unified DNS strategy with conditional forwarding between on-premises and cloud.
Consequences: High latency, unstable connection, name resolution issues between services, leading to non-functional distributed applications and costly downtime.
2. Ignoring Data Storage Strategy and Data Gravity
Mistake: Developers often move applications to the cloud without considering where their data resides. Or, conversely, they place databases on-premises and applications in the cloud, leading to high egress traffic costs and latency.
How to avoid:
- Analyze the nature of the data: volume, change rate, sensitivity, latency requirements.
- Place applications as close as possible to the data they intensively work with. If data is on-premises, then part of the applications working with it should also be on-premises.
- Use distributed storage (Rook/Ceph, Longhorn) on bare metal and corresponding cloud CSI drivers.
- Plan a data replication and backup strategy between environments.
Consequences: Unexpectedly high cloud traffic bills, poor application performance due to data access latency, data integrity issues without an adequate replication strategy.
3. Lack of a Unified IAM and RBAC Strategy
Mistake: Managing users and their access rights in each cluster separately, without a centralized system. This leads to chaos, security problems, and high operational costs.
How to avoid:
- Integrate Rancher with corporate LDAP/AD or an SSO provider for centralized authentication.
- Use global and cluster roles in Rancher for unified authorization management.
- Apply the principle of least privilege for all users and service accounts.
- Regularly audit access rights.
Consequences: Unauthorized access, security breaches, audit difficulties, high time costs for access management.
4. Inadequate Disaster Recovery (DR) Planning
Mistake: Many companies create hybrid infrastructure but do not test their DR plans or do not have them at all. Hoping that "nothing will happen" leads to catastrophic consequences in a real failure.
How to avoid:
- Define clear RTO and RPO for each mission-critical service.
- Develop a detailed DR plan, including backup, restore, failover to a standby cluster, and failback procedures.
- Use tools like Velero for automated backup and restoration of Kubernetes resources and data.
- Regularly (at least twice a year) conduct full-scale DR drills, simulating real failures.
Consequences: Prolonged downtime (hours or days), loss of mission-critical data, significant reputational and financial damage.
5. Underestimating Operational Complexity and the Need for Skilled Personnel
Mistake: Believing that Rancher will solve all problems and that hybrid Kubernetes can be managed by a single junior engineer. Hybrid infrastructure, even with Rancher, requires significant expertise in various areas (Kubernetes, networking, storage, cloud technologies, security).
How to avoid:
- Invest in team training. Ensure you have specialists with experience in Kubernetes, Rancher, as well as networking and cloud platforms.
- Start small, gradually increasing infrastructure complexity and team competencies.
- Automate routine tasks using CI/CD and GitOps.
- Consider using external expertise or consultants in the initial stages.
Consequences: Slow deployment, frequent incidents, low resource utilization efficiency, team burnout, high costs for finding and hiring highly qualified specialists.
6. Lack of Monitoring and Alerts for Hybrid Environments
Mistake: Deploying clusters in different environments but without centralized monitoring and logging. This leads to "blind spots" and the inability to quickly react to problems.
How to avoid:
- Implement a unified monitoring system (Prometheus/Grafana) and logging (ELK/Loki) for all clusters, regardless of their location.
- Configure metric and log aggregation in central storage for easy analysis.
- Define key health metrics for each component and set adequate thresholds for alerts.
- Ensure alerts are delivered to the correct channels (Slack, PagerDuty, email) and that there is a clear action plan for them.
Consequences: Long searches for incident causes, a reactive rather than proactive approach to management, high MTTR (Mean Time To Recovery).
By avoiding these common mistakes, you will significantly increase the chances of successful and efficient implementation of a hybrid Kubernetes infrastructure with Rancher.
Checklist for Practical Application
This checklist will help you systematize the planning and implementation process for a hybrid Kubernetes infrastructure with Rancher. Go through the items sequentially, ensuring that each step is completed or accounted for.
- Requirements Definition and Planning:
- [ ] Business goals and expected benefits from hybrid infrastructure are defined.
- [ ] Mission-critical applications and their performance, latency, security requirements are identified.
- [ ] Regulatory compliance requirements (GDPR, HIPAA, etc.) are determined.
- [ ] Current and projected data volumes and their "gravity" are analyzed.
- [ ] Budget for CapEx (bare metal) and OpEx (cloud, personnel, licenses) is formed.
- [ ] Team composition is formed and its competencies are assessed, training is planned if necessary.
- Component and Architecture Selection:
- [ ] Primary cloud provider (AWS, Azure, GCP) for cloud clusters is selected.
- [ ] Bare metal server specifications (CPU, RAM, Storage, Network) for on-premises clusters are determined.
- [ ] Kubernetes distribution (RKE/K3s for bare metal, EKS/AKS/GKE for cloud) is chosen.
- [ ] CNI plugin (Calico, Cilium) is selected, considering the hybrid environment.
- [ ] Data storage strategy is chosen (Rook/Ceph, Longhorn on-prem; cloud CSI drivers).
- [ ] Load balancing strategy is determined (MetalLB on-prem, cloud ALB/NLB, Ingress Controllers).
- Network Infrastructure Design:
- [ ] Non-overlapping IP ranges are allocated for all clusters and inter-cluster connections.
- [ ] Connection between on-premises and cloud is designed (VPN, Direct Connect/ExpressRoute).
- [ ] Unified DNS strategy with conditional forwarding is designed.
- [ ] Network security policies (Network Policies) are configured for pod isolation.
- Rancher and Cluster Deployment:
- [ ] Rancher management server is deployed (on-premises or in a dedicated cloud cluster).
- [ ] First bare metal Kubernetes cluster (RKE/K3s) is deployed and imported into Rancher.
- [ ] First cloud Kubernetes cluster (EKS/AKS/GKE) is deployed and imported into Rancher.
- [ ] Rancher integration with identity provider (LDAP/AD, SSO) is configured.
- Security and IAM Configuration:
- [ ] Global roles and RBAC are configured in Rancher for cluster management.
- [ ] RBAC is configured in each Kubernetes cluster for resource management.
- [ ] Secret management mechanism (Vault, External Secrets Operator) is implemented.
- [ ] Firewalls and security groups are configured for cluster and service isolation.
- CI/CD and GitOps Implementation:
- [ ] GitOps tool (ArgoCD, Flux) is selected and its integration with Git repository is configured.
- [ ] Helm charts or Kustomize configurations for applications are developed.
- [ ] CI/CD pipelines are configured for building images and deploying them in the hybrid environment.
- [ ] Rancher Fleet is implemented for managing application deployment at scale (optional).
- Monitoring, Logging, and Alerts:
- [ ] Prometheus and Grafana are deployed in each cluster or centrally.
- [ ] Log collection and aggregation (Fluentd/Fluent Bit + ELK/Loki) are configured.
- [ ] Key health metrics are defined and alerting rules are configured.
- [ ] Alert delivery channels (Slack, PagerDuty, email) are configured.
- Disaster Recovery (DR) Planning and Testing:
- [ ] RTO and RPO are defined for all mission-critical services.
- [ ] Tool for backing up and restoring Kubernetes resources and PVs (Velero) is implemented.
- [ ] Disaster recovery plan is developed and documented.
- [ ] Regular disaster recovery drills are conducted.
- Cost Optimization and Management:
- [ ] Tools for monitoring cloud costs and resource utilization are implemented.
- [ ] Automatic scaling policies (Cluster Autoscaler, HPA) are configured for efficient cloud resource utilization.
- [ ] Cost analysis and optimization opportunities are regularly sought.
- Documentation and Training:
- [ ] Complete documentation on architecture, configuration, and operational procedures is created.
- [ ] Team training on all aspects of the new infrastructure is conducted.
- [ ] Runbooks for typical operations and troubleshooting are developed.
By following this checklist, you can create a resilient, secure, and efficient hybrid Kubernetes infrastructure with Rancher, minimizing risks and maximizing return on investment.
Cost Calculation / Economics
Understanding the economics of hybrid infrastructure is critically important for making strategic decisions. Calculations can be complex, as they include both capital and operational expenditures, as well as hidden costs. We will examine examples of calculations for different scenarios in the context of 2026, taking into account inflation and technological trends.
Cost Components
- CapEx (Capital Expenditures) for Bare Metal:
- Servers: Cost of physical servers (CPU, RAM, disks). In 2026, powerful servers with 2x 64-core CPUs, 512GB RAM, 8x NVMe SSDs could cost from $15,000 to $30,000 each.
- Network Equipment: Switches, routers, cables. From $5,000 to $50,000 depending on scale.
- Storage: If distributed storage based on local disks is not used, external storage systems can cost from $20,000 to $100,000+.
- Racks, PDUs, KVM: Small but necessary expenses.
- OpEx (Operational Expenditures) for Bare Metal:
- Co-location: Fees for rack space, electricity, cooling, internet access. In 2026, this could be from $500 to $1,500 per month per rack with several servers.
- Personnel: Salaries of system administrators, DevOps engineers. This is one of the largest expense items.
- Licenses/Support: If commercial OS, software, or enterprise support for Rancher (Rancher Prime), Red Hat OpenShift are used.
- Maintenance: Replacement of failed components, warranty service.
- OpEx for Cloud:
- Compute Resources (vCPU, RAM): Cost of instances (VMs). In 2026, the cost of 1 vCPU/GB RAM may slightly decrease, but the total cost will grow with scale.
- Storage: EBS, Azure Disks, GCP Persistent Disks, S3-like storage.
- Network Traffic: Especially egress (outbound traffic). This is one of the most insidious hidden cost items.
- Managed Services: Cost of EKS/AKS/GKE Control Plane, managed databases, queues, load balancers.
- Reservations/Discounts: Reserved Instances, Savings Plans can significantly reduce costs if the load is predictable.
- Hidden Costs:
- Data Egress: Cost of data transfer out of the cloud can be very high ($0.05 - $0.15 per GB).
- Staff Training: Investment in team skill development.
- Inefficient Resource Utilization: Over-provisioning or under-utilization of resources.
- Downtime: Loss of profit, reputational damage.
- Security: Costs for security tools, auditing, incident response.
Cost Calculation Examples for Different Scenarios (2026 Forecast)
For example, let's take a medium-sized company that operates a workload equivalent to 10-15 modern physical servers (e.g., 200-300 vCPU, 1-2 TB RAM, 20-30 TB NVMe storage).
Scenario 1: Pure Bare Metal (with Rancher)
The company invests in its own hardware, using Rancher to simplify Kubernetes management. This is a choice for maximum control and performance, where CapEx is high, but OpEx is lower in the long run.
- CapEx (initial investment):
- 15 servers (2x64c/512GB/8xNVMe): 15 * $25,000 = $375,000
- Network equipment: $30,000
- Racks, PDUs: $10,000
- TOTAL CapEx: $415,000
- OpEx (monthly):
- Co-location (3 racks): 3 * $1,000 = $3,000
- Salary of 2 DevOps engineers (including overhead): 2 * $12,000 = $24,000
- Enterprise support for Rancher Prime (optional, $10-20K/year): ~$1,500
- Maintenance/replacement: $1,000
- TOTAL OpEx: $29,500/month
- TCO over 3 years: $415,000 (CapEx) + (36 * $29,500) (OpEx) = $415,000 + $1,062,000 = $1,477,000
Scenario 2: Pure Cloud (EKS/AKS/GKE)
The company relies entirely on managed cloud Kubernetes services. High flexibility, but potentially high OpEx at scale.
- CapEx: $0
- OpEx (monthly, without RI/Savings Plans):
- 15 instances (equivalent to 2x64c/512GB): 15 * $1,500 (e.g., m6i.16xlarge) = $22,500
- Storage (30TB GP3): $1,500
- EKS Control Plane: $730
- Network traffic (egress, 10TB/month): 10,000 * $0.08 = $800
- Other managed services (DB, Load Balancer, Monitoring): $3,000
- Salary of 2 DevOps engineers (less administration, more automation): 2 * $11,000 = $22,000
- TOTAL OpEx: $50,530/month
- TCO over 3 years: 36 * $50,530 = $1,819,080
- With Reserved Instances/Savings Plans (30-50% savings): $1,273,356 - $909,540
Scenario 3: Hybrid Infrastructure (with Rancher)
The company places 60% of the workload on bare metal (stable, resource-intensive services) and 40% in the cloud (elastic, temporary). Everything is managed through Rancher.
- CapEx (initial investment for 60% bare metal):
- 9 servers: 9 * $25,000 = $225,000
- Network equipment: $20,000
- Racks, PDUs: $5,000
- TOTAL CapEx: $250,000
- OpEx (monthly):
- Co-location (2 racks): 2 * $1,000 = $2,000 (bare metal part)
- Cloud resources (40% of scenario 2, with RI/SP): $50,530 * 0.4 * 0.7 = $14,148 (cloud part)
- Salary of 2 DevOps engineers (higher qualification required): 2 * $13,000 = $26,000
- Enterprise support for Rancher Prime: ~$1,500
- Bare metal maintenance: $600
- Direct Connect/ExpressRoute (for connectivity): $1,000
- TOTAL OpEx: $45,248/month
- TCO over 3 years: $250,000 (CapEx) + (36 * $45,248) (OpEx) = $250,000 + $1,628,928 = $1,878,928
- Note: Hybrid TCO may be higher than pure cloud with RI, but offers more control, security, and flexibility. Also, hybrid OpEx includes the salary of more qualified engineers. If the cloud part is more dynamic and does not use RI, then hybrid will be significantly cheaper.
How to Optimize Costs
- Resource Rightsizing: Regularly analyze resource consumption by your pods and nodes. Use VPA (Vertical Pod Autoscaler) and HPA (Horizontal Pod Autoscaler) for automatic scaling. Don't overpay for unused resources.
- Reserved Instances / Savings Plans: If you have a predictable baseline load in the cloud, use these mechanisms for significant savings (up to 70%).
- Spot Instances: For non-critical, interruptible workloads, use Spot Instances in the cloud for maximum savings (up to 90%).
- Network Traffic Optimization: Minimize egress traffic. Use CDN, caching, data compression. Place data close to applications.
- Efficient Bare Metal Utilization: Use Kubernetes to maximize resource utilization on physical servers. Consolidate workloads.
- Open Source Solutions: Maximize the use of free open-source tools (Rancher, Prometheus, Grafana, Velero, Longhorn) to avoid licensing fees.
- Automation: Invest in automation (GitOps, CI/CD) to reduce labor costs and minimize human errors.
Table with Calculation Examples (3-year TCO)
| Scenario | Initial CapEx (Bare Metal) | Monthly OpEx | 3-year TCO | Key Benefits |
|---|---|---|---|---|
| Pure Bare Metal (with Rancher) | ~$415,000 | ~$29,500 | ~$1,477,000 | High performance, full control, long-term savings for stable workloads. |
| Pure Cloud (EKS/AKS/GKE) | $0 | ~$50,530 (without RI/SP) | ~$1,819,080 | Maximum elasticity, quick start, minimal K8s administration. |
| (Cloud with RI/SP) | $0 | ~$35,000 | ~$1,260,000 | OpEx savings for predictable cloud workloads. |
| Hybrid (K8s with Rancher) | ~$250,000 | ~$45,248 | ~$1,878,928 | Balance of control, performance, and elasticity. Data security, DR. |
Note: These calculations are simplified estimates. Actual figures may vary significantly depending on specific requirements, discounts, regional prices, and operational efficiency. The key takeaway: a hybrid strategy is not always the cheapest in terms of TCO, but it offers an optimal balance between all critically important factors, which can ultimately provide greater business value.
Case Studies and Examples
Theory is important, but real-world examples of hybrid infrastructure with Kubernetes and Rancher provide the most complete picture of its advantages and challenges. Let's look at several realistic scenarios from various industries.
Case 1: Fintech Startup with High-Frequency Trading and Analytics
Problem:
A young, rapidly growing fintech startup developed an innovative platform for high-frequency trading (HFT) and predictive analytics. The HFT component required minimal latency (less than 1 ms) for order execution, as well as maximum throughput for processing market data. At the same time, the analytical block, which processed huge volumes of historical data and ran resource-intensive ML models, had unpredictable peak loads and required elasticity. Regulatory requirements mandated storing all transactional data within the country.
Solution with Rancher:
The company decided to create a hybrid infrastructure based on Kubernetes, managed by Rancher.
- On-premises Cluster (Bare Metal): A Kubernetes cluster was deployed on dedicated bare metal servers in their own data center. This cluster was used for HFT applications, transaction databases, and primary storage of sensitive financial data. RKE (Rancher Kubernetes Engine) was used for K8s deployment, MetalLB for Load Balancer, and Calico for CNI. Rook/Ceph was chosen for data storage, providing high performance and fault tolerance.
- Cloud Cluster (AWS EKS): An EKS cluster was deployed in AWS for analytical services, ML training, and public APIs. This cluster used Cluster Autoscaler for automatic node scaling based on load.
- Network Connectivity: AWS Direct Connect was configured between the on-premises data center and AWS to ensure a low-latency and high-speed connection. This allowed analytical services to securely access transactional data with minimal delay, and to transfer aggregated data to the cloud.
- Management with Rancher: Both clusters were imported and managed through a single Rancher interface. This allowed the DevOps team to unify deployment (via GitOps with ArgoCD), monitoring (Prometheus/Grafana), and access management (integration with corporate SSO) for both environments. Rancher Fleet was used for centralized deployment and updating of core components and applications across both clusters.
Results:
- Performance Optimization: HFT applications achieved the required <1 ms latency, providing a competitive advantage.
- Elasticity and Cost Savings: Analytical workloads scaled efficiently in the cloud, paying only for used resources, which avoided excessive bare metal investments for peaks.
- Regulatory Compliance: Sensitive transactional data remained on their own servers, fully complying with local data sovereignty requirements.
- Simplified Management: Rancher significantly reduced operational overhead by providing a single point of control over a complex hybrid environment.
- Improved DR: Backups of mission-critical data from bare metal were replicated to S3-compatible storage in AWS, ensuring a reliable disaster recovery plan.
Case 2: Large Medical Institution with EHR System
Problem:
A large network of clinics used an outdated monolithic Electronic Health Record (EHR) system on on-premises servers. The system was critically important, required high availability, and complied with strict HIPAA and other medical standards. The clinic also wanted to develop new, publicly accessible services (patient portal, telemedicine) using modern technologies, but could not risk the security of sensitive data.
Solution with Rancher:
A strategy of gradual modernization and hybrid deployment was chosen.
- On-premises Cluster (Bare Metal): Existing physical servers were upgraded, and a Kubernetes cluster (RKE) was deployed on them to host the EHR system and its associated databases. This ensured maximum control over patient data and HIPAA compliance. "Lift-and-shift" techniques and gradual decomposition into microservices were used to migrate the monolith to containers.
- Cloud Cluster (Azure AKS): An AKS cluster was deployed in Azure for new public services (patient portal, telemedicine APIs, mobile backends). These services did not store sensitive data directly but accessed the EHR system through secure APIs.
- Network Connectivity and Security: Azure ExpressRoute was configured between the on-premises data center and Azure for secure and high-performance connectivity. Strict network policies and firewalls were implemented, as well as OPA Gatekeeper for enforcing security policies in Kubernetes.
- Management with Rancher: Rancher was used to manage both clusters. This allowed the IT team to apply unified RBAC policies, manage the cluster lifecycle, and deploy applications using GitOps. Special attention was paid to monitoring (Prometheus/Grafana) and auditing (Fluentd/Loki) to ensure compliance with regulatory requirements.
Results:
- Compliance and Security: Sensitive patient data remained under full control on-premises, ensuring HIPAA compliance. Public services were isolated in the cloud.
- Modernization: The clinic was able to modernize its outdated EHR system, gradually transitioning it to a microservices architecture without interrupting critical services.
- Innovation: The ability to quickly deploy new patient services in the cloud, using modern technologies and flexibility, was gained.
- High Availability: The on-premises cluster was configured with redundancy, and the cloud cluster provided DR for public services.
Case 3: SaaS Provider Aiming for Cost Optimization
Problem:
A medium-sized SaaS provider offering B2B solutions operated entirely in AWS on EKS. As the customer base grew and data volumes increased, monthly bills for cloud resources (especially for databases, storage, and egress traffic) grew exponentially, threatening business profitability. Performance issues were also observed for some resource-intensive analytical reports.
Solution with Rancher:
The company decided to migrate part of its workloads to bare metal, creating a hybrid infrastructure.
- On-premises Cluster (Bare Metal): The company leased several racks in a co-location center and deployed a Kubernetes cluster (RKE) on bare metal servers. Core databases (PostgreSQL, ClickHouse) were migrated here, as well as services generating large data volumes and requiring high performance for analytics. Longhorn was chosen for storage.
- Cloud Cluster (AWS EKS): An EKS cluster remained in AWS, hosting frontend applications, API gateways, and microservices that had highly fluctuating loads and required rapid scalability.
- Network Connectivity: AWS Direct Connect was configured between the co-location center and AWS to ensure fast and cost-effective communication between cloud microservices and on-premises databases.
- Management with Rancher: Rancher was deployed as a central management node in a separate, small cluster in AWS. It was used for unified management of both clusters, application deployment via GitOps (ArgoCD), and centralized monitoring.
Results:
- Significant Savings: Migrating databases and high-load backends to bare metal reduced monthly OpEx by 35-40%, especially by cutting costs on cloud databases and egress traffic.
- Improved Performance: Analytical reports were generated faster due to direct access to powerful bare metal hardware.
- Preserved Flexibility: Frontends and API gateways continued to scale in the cloud, ensuring high availability and responsiveness for users.
- Reduced Vendor Lock-in: The company gained the ability to use different cloud providers in the future and not be entirely dependent on AWS.
These case studies demonstrate that hybrid infrastructure with Kubernetes and Rancher is a powerful tool for solving a wide range of business challenges, from optimizing performance and complying with regulatory requirements to significant cost savings and increased flexibility.
Tools and Resources
Successful construction and management of a hybrid Kubernetes infrastructure with Rancher requires a set of proven tools and access to up-to-date resources. Here is a list of key categories and specific examples, relevant for 2026.
1. Core Platforms
- Rancher: Official Website
A central platform for managing multiple Kubernetes clusters deployed anywhere: on bare metal, in virtual machines, in private and public clouds. Provides a unified UI, API, and CLI for managing cluster lifecycle, deploying applications, and ensuring security.
- Kubernetes (K8s): Official Website
An open-source platform for automating deployment, scaling, and management of containerized applications. The foundation of the entire hybrid strategy.
- RKE (Rancher Kubernetes Engine): Official Documentation
A certified Kubernetes distribution from Rancher, ideal for deployment on bare metal and virtual machines, as well as for edge scenarios.
- K3s: Official Website
A lightweight, certified Kubernetes, optimized for edge, IoT, and bare metal environments with limited resources. Managed by Rancher.
- Cloud K8s Services:
- Amazon EKS: Official Website
- Azure AKS: Official Website
- Google GKE: Official Website
Managed Kubernetes services from leading cloud providers.
2. Network Tools (CNI, Load Balancer, Connectivity)
- Calico: Official Website
A popular CNI plugin for Kubernetes, providing network connectivity, security policies, and BGP support, making it an excellent choice for hybrid and bare metal environments.
- Cilium: Official Website
Another advanced CNI based on eBPF, offering high performance, advanced network policies, and observability.
- MetalLB: Official Website
A load balancer implementation for bare metal Kubernetes clusters, using standard routing protocols (ARP, BGP).
- Ingress Controllers (NGINX, Traefik, Istio Ingress Gateway):
- NGINX Ingress Controller: Official GitHub
- Traefik: Official Website
- Istio: Official Website (as part of a service mesh)
For routing external HTTP/S traffic to services inside the cluster.
- Inter-network Connectivity Tools:
- OpenVPN / WireGuard: For creating secure tunnels between on-premises and cloud.
- AWS Direct Connect / Azure ExpressRoute / Google Cloud Interconnect: Dedicated network connections for high performance and security.
3. Data Storage Systems (CSI)
- Rook (Ceph): Official Website
A Kubernetes operator that deploys and manages distributed Ceph storage, turning a Kubernetes cluster into a self-scaling, self-healing storage system (block, file, object).
- Longhorn: Official Website
Distributed block storage for Kubernetes from Rancher, simple to deploy and manage, ideal for bare metal and edge.
- Cloud CSI Drivers:
Drivers for integrating Kubernetes with native cloud storage.
4. CI/CD and GitOps
- ArgoCD: Official Website
A declarative, GitOps-oriented continuous delivery tool for Kubernetes. Excellent for managing deployments in multi-cluster environments.
- Flux: Official Website
Another popular GitOps operator that provides continuous delivery and synchronization of cluster state with a Git repository.
- Rancher Fleet: Official Website
A tool for centrally managing a fleet of thousands of Kubernetes clusters, deploying applications, and managing configurations at scale.
- Jenkins / GitLab CI / GitHub Actions:
Traditional CI tools for building images, running tests, and triggering GitOps pipelines.
5. Monitoring, Logging, and Alerting
- Prometheus: Official Website
An open-source monitoring and alerting system, the de facto standard for Kubernetes monitoring.
- Grafana: Official Website
A platform for visualizing metrics aggregated by Prometheus, as well as logs from Loki.
- Loki: Official Website
A log aggregation system optimized for Kubernetes, working on the principle of "metrics for logs".
- ELK Stack (Elasticsearch, Logstash, Kibana): Official Website
A powerful stack for collecting, analyzing, and visualizing logs at scale.
- Fluentd / Fluent Bit: Official Website / Official Website
Lightweight agents for collecting logs from containers and sending them to central storage.
6. Security and Secret Management
- Vault (HashiCorp): Official Website
A tool for securely storing and managing secrets, API keys, tokens, and other sensitive data.
- OPA Gatekeeper: Official GitHub
A Kubernetes operator that enforces Open Policy Agent (OPA) policies to ensure cluster compliance with defined rules (e.g., prohibiting the running of privileged containers).
- Falco: Official Website
A real-time security threat detection engine for Kubernetes and containers.
7. Disaster Recovery (DR)
- Velero: Official Website
An open-source tool for safely backing up and restoring Kubernetes resources and persistent volumes.
8. Useful Links and Documentation
- Official Kubernetes Documentation: kubernetes.io/docs/
- Official Rancher Documentation: rancher.com/docs/
- CNCF Landscape: landscape.cncf.io
An interactive map of Cloud Native Computing Foundation projects, useful for finding tools.
- Blogs and Communities:
- Kubernetes Blog
- Rancher Blog
- Stack Overflow (kubernetes, rancher tags)
- Reddit (r/kubernetes, r/devops)
Using this set of tools and continuously referring to up-to-date resources will enable your team to effectively build, maintain, and evolve a hybrid Kubernetes infrastructure with Rancher.
Troubleshooting
Even in the most carefully designed hybrid infrastructure, problems arise. It is important to have a clear algorithm for diagnosis and troubleshooting. Rancher, thanks to its centralized dashboard, often helps quickly pinpoint the source of a problem, but a deep understanding of Kubernetes and the underlying infrastructure remains key.
1. Common Kubernetes Cluster Problems
Problem: Node is NotReady
Diagnosis:
kubectl get nodes
kubectl describe node <node-name>
journalctl -u kubelet -f # On the problematic node
- Check the node's network connectivity.
- Ensure kubelet is running and not reporting errors.
- Check resource utilization (CPU, RAM, disk space) on the node. The node might be overloaded.
- Check the CNI plugin: is it working correctly on the node?
Problem: Pod is in Pending, CrashLoopBackOff, ImagePullBackOff state
Diagnosis:
kubectl get pods -o wide # To see which node the pod is on
kubectl describe pod <pod-name> -n <namespace>
kubectl logs <pod-name> -n <namespace> # For CrashLoopBackOff
- Pending: Check node resources (CPU/RAM). Ensure there are available nodes with sufficient resources. Check
Eventsinkubectl describe podfor VolumeMounts or Network issues. - CrashLoopBackOff: Application issue. Check pod logs. Possibly incorrect configuration, code error, or insufficient resources.
- ImagePullBackOff: Problem accessing the image registry. Check image name, registry availability, and credentials (ImagePullSecrets).
2. Network Problems
Problem: Service is inaccessible from outside or between pods
Diagnosis:
kubectl get svc <service-name> -n <namespace>
kubectl get ep <service-name> -n <namespace> # Check for Endpoints
kubectl get networkpolicy -n <namespace> # If CNI with NetworkPolicy is used
ip route show # On the node where the pod is running
- Verify that the service has Endpoints (the pods it serves must be running and healthy).
- Ensure Network Policies are not blocking traffic.
- Check Load Balancer (MetalLB on-prem, cloud LB) or Ingress Controller settings.
- For inter-pod communication: check the CNI plugin and its logs.
- For inter-cluster communication in a hybrid setup: check VPN/Direct Connect, routing, firewalls.
Problem: DNS resolution issues between on-premises and cloud clusters
Diagnosis:
kubectl exec -it <pod-name> -n <namespace> -- nslookup <hostname>
- Check CoreDNS configuration in Kubernetes (ConfigMap).
- Ensure conditional forwarders are correctly configured on CoreDNS and on your on-premises DNS servers.
- Check DNS server accessibility via VPN/Direct Connect.
3. Storage Problems
Problem: PersistentVolumeClaim (PVC) stuck in Pending state
Diagnosis:
kubectl get pvc <pvc-name> -n <namespace>
kubectl describe pvc <pvc-name> -n <namespace>
kubectl get storageclass
- Check if the StorageClass specified in the PVC exists.
- Ensure the CSI driver for that StorageClass is deployed and running in the cluster.
- Check CSI controller logs (e.g.,
kubectl logs -f <csi-driver-pod> -n <csi-namespace>). - For Rook/Ceph or Longhorn: check the operator's status and its pods.
- For cloud PVs: check quotas and availability of cloud storage.
4. Rancher Problems
Problem: Cluster not importing or in "Unavailable" state
Diagnosis:
- Check Rancher Server logs (
kubectl logs -f <rancher-pod> -n cattle-system). - On the problematic cluster: check Rancher Agent logs (
kubectl logs -f <cattle-cluster-agent-pod> -n cattle-system). - Ensure network connectivity between Rancher Server and the problematic cluster (port 443).
- Verify that the Rancher Agent has sufficient RBAC permissions in the cluster.
- Resolve network issues.
- Restart the Rancher Agent on the problematic cluster.
- In extreme cases, remove the Rancher Agent from the cluster and try importing it again.
5. Hybrid Environment Problems
Problem: Latency or packet loss between on-premises and cloud clusters
Diagnosis:
ping <ip-address-in-other-cluster>
traceroute <ip-address-in-other-cluster>
# On network equipment: check Direct Connect/ExpressRoute statistics, VPN tunnel logs.
- Check the status of Direct Connect/ExpressRoute or the VPN tunnel.
- Ensure firewalls and security groups (in the cloud) are not blocking traffic.
- Check routing tables on all intermediate devices.
- Assess connection bandwidth. It might be insufficient for the current load.
When to Contact Support
- Unresolvable critical failures: If the cluster is completely inoperable and you have exhausted all your diagnostic capabilities.
- Underlying hardware issues: Server, network equipment, storage failures on bare metal.
- Managed cloud service issues: If the EKS/AKS/GKE Control Plane is behaving incorrectly, or there are failures in the cloud network/storage.
- Rancher Enterprise Prime issues: If you have commercial Rancher support, contact them for problems with the Rancher platform itself.
- Lack of expertise: If the problem is beyond your team's competence.
A systematic approach to troubleshooting, good documentation, and a skilled DevOps team are fundamental to maintaining the stability of any, especially hybrid, infrastructure.
FAQ
Why do I need a hybrid infrastructure if I can just use the cloud?
Pure cloud is great for quick starts and high elasticity, but at scale, it can become very expensive, especially for stable, resource-intensive workloads and egress traffic. Hybrid allows you to optimize costs by placing predictable and performance-critical services on your own servers (bare metal), and elastic and temporary ones in the cloud. It also gives you more control over data and facilitates compliance with regulatory requirements.
Can I manage hybrid Kubernetes without Rancher?
Theoretically yes, but in practice, it's extremely difficult. Without Rancher, you would have to manage each Kubernetes cluster separately, using native provider tools or kubectl. This would lead to significant operational overhead, configuration inconsistencies, increased monitoring complexity, and security challenges. Rancher unifies management, providing a single pane of glass for all clusters, regardless of their location, which significantly reduces complexity and OpEx.
Which CNI plugins are best suited for hybrid Kubernetes clusters?
For hybrid environments, CNI plugins that support network policies and provide high performance are excellent. Calico and Cilium are leaders in this area. They can operate in various modes, support BGP for integration with bare metal networks, and allow for the creation of complex network policies to isolate traffic between pods, which is critical for security in a distributed environment.
How to ensure the security of sensitive data in a hybrid infrastructure?
The key to security is segmentation and control. Place the most sensitive data and applications on bare metal servers where you have full control over physical and logical security. Use strict network policies, encryption of data at rest and in transit, and centralized identity management (IAM) through Rancher. Regularly conduct audits and use tools like OPA Gatekeeper to enforce security policies in Kubernetes.
What is the difference between Bare Metal and virtual machines on my own hardware?
Bare metal is the direct use of physical servers, without a virtualization layer. This provides maximum performance, as there is no hypervisor overhead. Virtual machines (VMs) on your own hardware imply the presence of a hypervisor (e.g., VMware vSphere, KVM) that creates virtual machines. VMs offer greater flexibility in resource management but add a small overhead. For Kubernetes, bare metal is often chosen for the most performance-demanding workloads.
How to manage Kubernetes updates in a hybrid environment?
Rancher significantly simplifies update management. You can use Rancher to orchestrate updates for RKE or K3s clusters on bare metal, as well as for managed cloud clusters (EKS/AKS/GKE). It is recommended to have a clear process: first update dev/test clusters, conduct regression testing, then staging, and only then production. Rancher provides a convenient UI for this, minimizing manual operations.
What are the risks of transitioning to a hybrid infrastructure?
Key risks include: high initial complexity of design and implementation, significant investment in skilled personnel, potential problems with network integration and data management, and hidden costs of inter-cloud traffic. However, these risks can be minimized through careful planning, phased implementation, the use of reliable tools like Rancher, and team training.
Can different Kubernetes versions be used in different clusters of a hybrid environment?
Yes, this is one of the strengths of a hybrid approach with Rancher. Rancher allows managing clusters with different Kubernetes versions. This is useful for testing new versions, gradual upgrades, or maintaining compatibility with legacy applications. However, for mission-critical applications, it is recommended to strive for version uniformity to simplify management and reduce compatibility risks.
How to scale bare metal clusters?
Scaling bare metal clusters requires adding physical servers. This does not happen instantly, as in the cloud. The process involves procurement, installation, OS configuration, and adding nodes to the Kubernetes cluster. Rancher simplifies the last step, allowing easy addition of new nodes to an existing RKE/K3s cluster. Effective bare metal scaling requires careful capacity planning and automation of the new server deployment process (e.g., using PXE boot and Ansible).
How complex is migrating existing applications to hybrid Kubernetes?
The complexity of migration depends on the application's architecture. Monolithic applications may require significant effort for containerization and decomposition into microservices. Cloud-native applications are easier to migrate. Rancher and Kubernetes provide the platform, but the migration itself requires dependency analysis, configuration rewriting, and thorough testing. It is recommended to start with "lift-and-shift" for simple applications, and then gradually modernize them.
Conclusion
In 2026, managing hybrid infrastructure, especially using Kubernetes on bare metal and in the cloud in conjunction with Rancher, is not just a technical choice but a strategic necessity for many organizations. We have thoroughly examined key factors such as cost, performance, security, scalability, and management overhead, demonstrating how a hybrid approach allows achieving an optimal balance between them.
Bare metal provides unparalleled performance and full control for mission-critical and resource-intensive workloads, while the cloud offers unprecedented elasticity and deployment speed for dynamic and scalable services. Rancher acts as the connecting link, unifying management, monitoring, and security across these heterogeneous environments. This allows DevOps engineers, developers, and CTOs to focus on creating business value rather than struggling with infrastructure complexity.
We emphasized the importance of detailed planning for network architecture, data storage strategy, centralized IAM, robust CI/CD, and a comprehensive approach to disaster recovery. Avoiding common mistakes, such as underestimating network complexity or lacking an adequate DR plan, is key to success. TCO calculation examples showed that, while hybrid infrastructure may have higher initial CapEx, it often provides better long-term savings and strategic flexibility compared to pure cloud solutions, especially with stable, high-load components.
Real-world case studies from fintech, healthcare, and SaaS sectors demonstrated how companies use hybrid with Rancher to solve specific business challenges: from ensuring low latency for HFT and complying with strict regulatory requirements to significant optimization of cloud costs.
Final Recommendations:
- Plan Thoroughly: Start with a deep analysis of your business needs, performance requirements, security, and budget.
- Start Small: Don't try to migrate your entire infrastructure at once. Choose a pilot project or a non-critical application to begin, to gain experience.
- Invest in Your Team: Hybrid infrastructure requires highly skilled professionals. Provide training and development of your team's competencies.
- Automate Everything: Use GitOps and CI/CD for maximum automation of deployment, management, and monitoring.
- Don't Forget Security and DR: These are not options, but mandatory components of your strategy. Regularly test your plans.
- Use Rancher: This is a critically important tool for unifying management and reducing operational overhead in a hybrid environment.
Next Steps for the Reader:
- Conduct an internal audit of your current infrastructure and business requirements.
- Study Rancher and Kubernetes documentation, experiment with deploying a small RKE or K3s cluster.
- Build a pilot hybrid scenario, for example, by deploying several microservices in the cloud and a database on bare metal, managing them through Rancher.
- Start planning a detailed network architecture and data storage strategy for your future hybrid infrastructure.
Hybrid infrastructure with Kubernetes and Rancher is a powerful foundation for building a flexible, resilient, and cost-effective IT environment capable of adapting to the rapidly changing demands of the modern digital world.