Оптимизация высокопроизводительного AI/ML инференса на GPU: Triton Inference Server и лучшие практики (2026 год)
TL;DR
- Triton Inference Server — это де-факто стандарт для высокопроизводительного AI/ML инференса на GPU, обеспечивающий низкую задержку и высокую пропускную способность благодаря пакетной обработке, параллелизму моделей и динамической загрузке.
- Ключевые факторы успеха в 2026 году включают выбор правильного GPU (NVIDIA Blackwell B200/GB200 или AMD Instinct MI400), эффективную квантизацию моделей (INT8, FP8) и использование продвинутых техник компиляции (TensorRT).
- Масштабирование инференса наилучшим образом достигается через Kubernetes с операторами типа KServe или Seldon Core, что позволяет динамически управлять ресурсами и обеспечивать отказоустойчивость.
- Мониторинг и профилирование критически важны: Prometheus, Grafana и NVIDIA DCGM помогут выявить узкие места в производительности и оптимизировать использование GPU.
- Экономия затрат достигается за счет точного подбора GPU инстансов, агрессивной оптимизации моделей, использования спотовых инстансов в облаке и эффективного управления жизненным циклом моделей.
- Типичные ошибки включают недооценку сложности развертывания, игнорирование оптимизации моделей до деплоя, отсутствие адекватного мониторинга и неправильную конфигурацию пакетной обработки.
- Будущее инференса движется к мультимодальным и сверхбольшим моделям, требующим распределенного инференса и еще более изощренных стратегий для оптимизации использования памяти и вычислений.
Введение
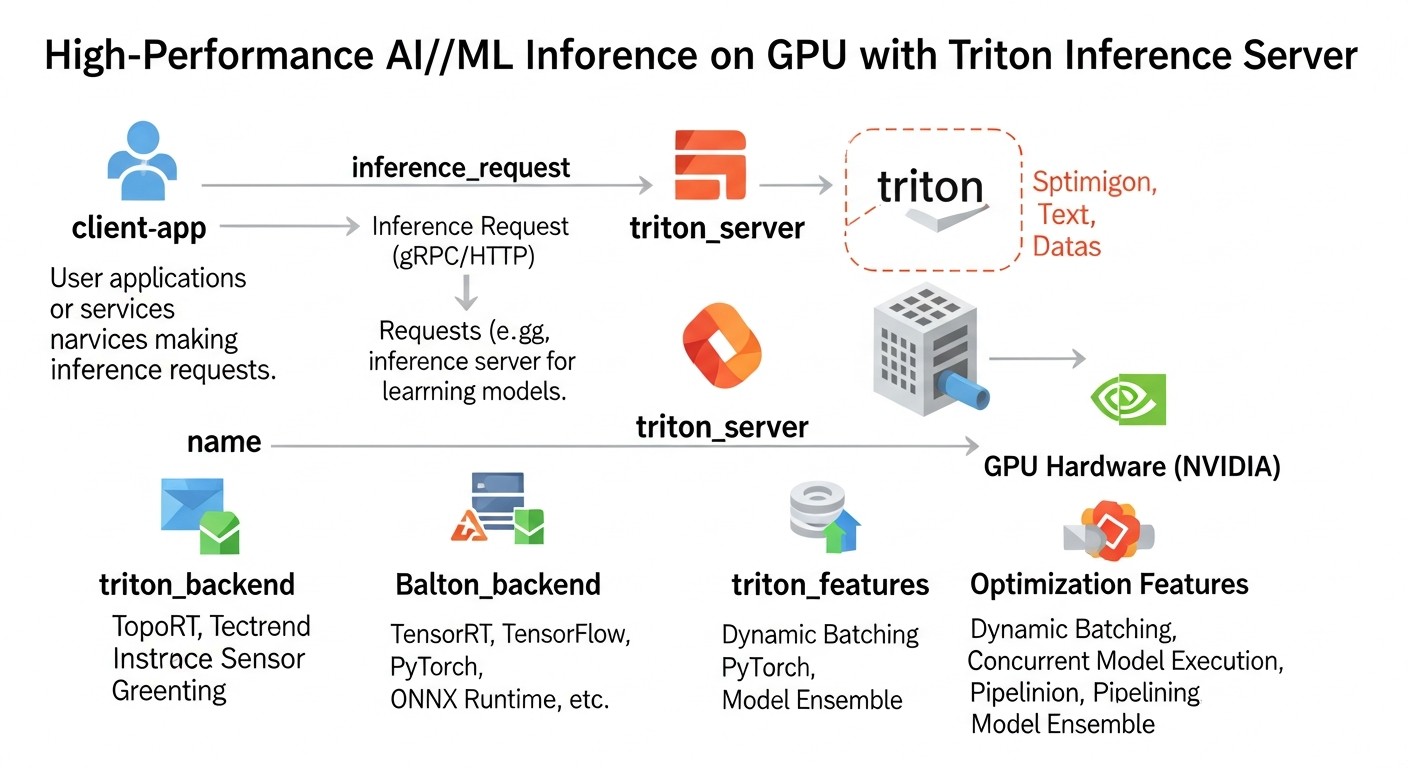 Схема: Введение
Схема: Введение
В 2026 году, когда искусственный интеллект и машинное обучение стали неотъемлемой частью практически каждой отрасли, от автономного транспорта до персонализированной медицины, критически важным аспектом становится не только разработка мощных моделей, но и их эффективное развертывание. Высокопроизводительный инференс на GPU — это не просто желаемая функция, а строгое требование для большинства современных AI-приложений. Пользователи ожидают мгновенных ответов, а бизнес требует масштабируемости и экономической эффективности.
Проблемы, с которыми сталкиваются команды, многочисленны: как обслуживать миллионы запросов в секунду с минимальной задержкой? Как максимально эффективно использовать дорогие GPU-ресурсы? Как управлять десятками или сотнями различных моделей, каждая со своими требованиями к фреймворкам и версиям? Как обеспечить высокую доступность и отказоустойчивость в условиях постоянно растущей нагрузки?
Эта статья адресована DevOps-инженерам, backend-разработчикам, фаундерам SaaS-проектов, системным администраторам и техническим директорам стартапов, которые стремятся построить надежную, масштабируемую и экономичную инфраструктуру для AI/ML инференса. Мы сфокусируемся на NVIDIA Triton Inference Server как на золотом стандарте в этой области, предоставив глубокий анализ его возможностей, лучшие практики и конкретные примеры, актуальные для технологического ландшафта 2026 года.
Мы рассмотрим не только технические аспекты Triton, но и более широкие вопросы, такие как выбор оборудования, оптимизация моделей, интеграция с оркестраторами типа Kubernetes, мониторинг и управление затратами. Цель — дать вам исчерпывающее руководство, которое позволит принимать обоснованные решения и успешно внедрять высокопроизводительный инференс в ваших проектах.
Основные критерии и факторы оптимизации высокопроизводительного инференса
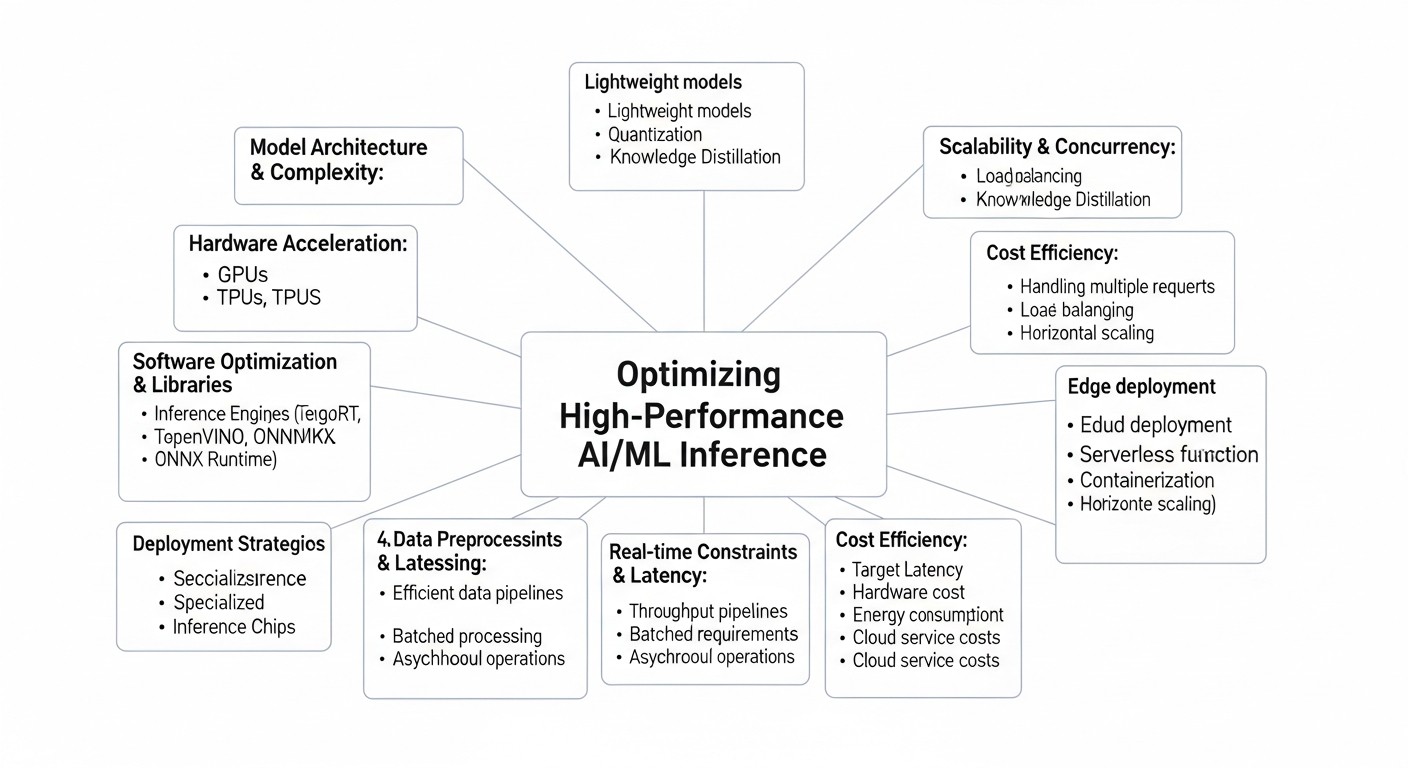 Схема: Основные критерии и факторы оптимизации высокопроизводительного инференса
Схема: Основные критерии и факторы оптимизации высокопроизводительного инференса
Для достижения оптимальной производительности и эффективности AI/ML инференса на GPU необходимо учитывать множество факторов. Каждый из них играет ключевую роль в общей архитектуре и может стать как узким местом, так и мощным рычагом оптимизации. Рассмотрим их детально.
1. Задержка (Latency)
Задержка — это время, необходимое для получения ответа от модели после отправки запроса. Для интерактивных приложений (например, чат-ботов, систем рекомендаций в реальном времени, автономного вождения) низкая задержка критически важна. Пользователи ожидают ответов в пределах десятков или сотен миллисекунд. Высокая задержка приводит к плохому пользовательскому опыту и может сделать продукт непригодным.
- Почему важна: Прямо влияет на UX, особенно в real-time сценариях.
- Как оценивать: Измеряется в миллисекундах (ms). Важно смотреть на p90, p95, p99 задержки, а не только на среднее значение, чтобы учесть выбросы.
- Факторы влияния: Размер модели, сложность вычислений, тип GPU, размер пакета (batch size), сетевые задержки, накладные расходы сервера инференса.
2. Пропускная способность (Throughput)
Пропускная способность — это количество запросов, которые система может обработать за единицу времени (например, запросов в секунду). Это ключевой показатель для высоконагруженных систем, где необходимо обслуживать большое количество параллельных запросов, таких как обработка изображений, видеопотоков или текстовых документов.
- Почему важна: Определяет масштабируемость системы и способность справляться с пиковыми нагрузками.
- Как оценивать: Измеряется в запросах в секунду (RPS) или инференсах в секунду.
- Факторы влияния: Количество GPU, их вычислительная мощность, размер пакета, эффективность параллелизации, накладные расходы на I/O.
3. Использование ресурсов GPU (GPU Utilization)
Эффективное использование GPU — это максимизация вычислительной мощности дорогостоящего оборудования. Низкая утилизация означает, что вы платите за простаивающие ресурсы. Цель состоит в том, чтобы держать GPU загруженным как можно ближе к 100%, не жертвуя при этом задержкой.
- Почему важна: Прямо влияет на операционные расходы. Недостаточная утилизация — это потерянные деньги.
- Как оценивать: Мониторинг утилизации GPU (SM utilization, memory utilization) с помощью инструментов типа
nvidia-smi, DCGM.
- Факторы влияния: Размер пакета, количество параллельных моделей, эффективность планирования задач на GPU, накладные расходы CPU, скорость передачи данных.
4. Экономическая эффективность (Cost-Effectiveness)
Отношение производительности к стоимости. Это не только прямые затраты на GPU, но и расходы на электроэнергию, охлаждение, обслуживание, лицензии (если применимо) и оплату труда инженеров. В 2026 году, с появлением более мощных и специализированных GPU, таких как NVIDIA Blackwell B200/GB200 или AMD Instinct MI400, их высокая стоимость делает вопрос экономической эффективности еще более острым.
- Почему важна: Определяет долгосрочную жизнеспособность и прибыльность AI-продукта.
- Как оценивать: Расчет TCO (Total Cost of Ownership) и метрик типа "стоимость за инференс" или "стоимость за 1000 запросов".
- Факторы влияния: Выбор оборудования (облако/on-premise, тип GPU), оптимизация моделей, эффективное масштабирование, использование спотовых инстансов.
5. Поддержка различных фреймворков и моделей (Framework/Model Support)
Современные AI-системы часто используют модели, разработанные с использованием различных фреймворков (TensorFlow, PyTorch, ONNX, JAX, Hugging Face Transformers) и в разных форматах. Сервер инференса должен обеспечивать гибкость в работе с этим разнообразием.
- Почему важна: Позволяет централизованно управлять развертыванием, избегая зоопарка из отдельных сервисов для каждой модели.
- Как оценивать: Список поддерживаемых фреймворков и форматов моделей, легкость добавления новых.
- Факторы влияния: Архитектура сервера инференса (модульная, плагинная), наличие готовых бэкендов.
6. Масштабируемость (Scalability)
Способность системы увеличивать или уменьшать свои ресурсы в зависимости от изменения нагрузки. Это включает как горизонтальное масштабирование (добавление новых инстансов сервера), так и вертикальное (использование более мощных GPU или нескольких GPU на одном инстансе).
- Почему важна: Обеспечивает стабильную работу при пиковых нагрузках и экономию ресурсов в периоды низкой активности.
- Как оценивать: Тестирование под нагрузкой, способность интегрироваться с оркестраторами (Kubernetes).
- Факторы влияния: Архитектура приложения, контейнеризация, использование Kubernetes, политики автомасштабирования.
7. Простота развертывания и управления (Ease of Deployment & Management)
Сложность настройки, деплоя, обновления и мониторинга моделей и самого сервера инференса. Чем проще эти процессы, тем меньше времени и ресурсов требуется от DevOps-команды.
- Почему важна: Снижает операционные издержки и ускоряет цикл разработки/развертывания.
- Как оценивать: Время, необходимое для развертывания новой модели, сложность конфигурации, наличие API для управления.
- Факторы влияния: Документация, готовые образы Docker, Helm-чарты, наличие управляющих API.
8. Надежность и отказоустойчивость (Reliability & Fault Tolerance)
Способность системы продолжать функционировать даже при сбоях отдельных компонентов. Это критично для production-систем, где простой может привести к значительным финансовым потерям.
- Почему важна: Обеспечивает непрерывность сервиса и предотвращает потери данных или доходов.
- Как оценивать: Время восстановления после сбоя (RTO), допустимая потеря данных (RPO), тестирование сбоев.
- Факторы влияния: Использование оркестраторов (Kubernetes), балансировщиков нагрузки, дублирование компонентов, механизмы самовосстановления.
9. Безопасность (Security)
Защита моделей, данных и инфраструктуры от несанкционированного доступа, изменений или утечек. Включает аутентификацию, авторизацию, шифрование данных в пути и в покое.
- Почему важна: Защита интеллектуальной собственности (моделей), конфиденциальных данных клиентов и соответствие регуляторным требованиям (GDPR, HIPAA).
- Как оценивать: Наличие механизмов аутентификации/авторизации, поддержка TLS, изоляция ресурсов.
- Факторы влияния: Интеграция с корпоративными системами безопасности, использование контейнеров с минимальными привилегиями, регулярные аудиты безопасности.
10. Версионирование моделей и A/B-тестирование (Model Versioning & A/B Testing)
Возможность управлять различными версиями одной модели, плавно переключаться между ними, а также направлять часть трафика на новую версию для тестирования перед полным развертыванием.
- Почему важна: Позволяет безопасно обновлять модели, проводить эксперименты и минимизировать риски при деплое.
- Как оценивать: Наличие встроенных механизмов версионирования и маршрутизации трафика, интеграция с CI/CD пайплайнами.
- Факторы влияния: Функциональность сервера инференса, поддержка Kubernetes Ingress/Service Mesh.
Сравнительная таблица подходов к инференсу на GPU (2026 год)
 Схема: Сравнительная таблица подходов к инференсу на GPU (2026 год)
Схема: Сравнительная таблица подходов к инференсу на GPU (2026 год)
Выбор правильного подхода к развертыванию AI/ML моделей на GPU критически важен. В 2026 году существуют несколько зрелых стратегий, каждая со своими сильными и слабыми сторонами. В этой таблице мы сравним наиболее распространенные варианты, учитывая актуальные технологии и ценовые реалии.
| Критерий |
"Сырой" API (FastAPI + PyTorch/TF) |
ONNX Runtime Inference Server |
NVIDIA Triton Inference Server |
KServe / Seldon Core (на Kubernetes) |
| Задержка (Latency) |
Средняя (зависит от кастомной оптимизации, нет динамического батчинга) |
Низкая (оптимизирован для ONNX, эффективная работа с CPU/GPU) |
Очень низкая (динамический батчинг, мультимодельный параллелизм, TensorRT) |
Низкая (использует Triton/ONNX RT/TF Serving под капотом, но с доп. накладными расходами Kubernetes) |
| Пропускная способность (Throughput) |
Средняя (требует ручной реализации батчинга) |
Высокая (эффективное использование ресурсов) |
Очень высокая (максимальное использование GPU, параллельные запросы) |
Очень высокая (горизонтальное масштабирование Kubernetes, автоскейлинг) |
| Использование GPU |
Среднее (может быть неоптимальным без ручной настройки) |
Высокое (хорошо оптимизирован) |
Очень высокое (динамический батчинг, планировщик, мульти-GPU) |
Высокое (эффективное выделение ресурсов через Kubernetes) |
| Сложность развертывания |
Низкая для простых моделей, высокая для оптимизации |
Средняя (нужен ONNX-формат) |
Средняя-Высокая (конфигурация моделей, бэкенды) |
Высокая (требует глубоких знаний Kubernetes) |
| Поддержка фреймворков |
Любые (поскольку код пишется вручную) |
ONNX (конвертация из PyTorch/TF/etc.) |
TensorFlow, PyTorch, ONNX, TensorRT, OpenVINO, custom backends |
Любые (через интеграцию с TF Serving, PyTorch Serve, Triton, ONNX RT) |
| Масштабируемость |
Ручное горизонтальное масштабирование, нет автоскейлинга GPU |
Горизонтальное масштабирование инстансов |
Горизонтальное масштабирование инстансов, внутренний мульти-GPU |
Автоматическое горизонтальное и вертикальное масштабирование на Kubernetes |
| Версионирование/A/B-тестирование |
Ручная реализация |
Через развертывание разных инстансов |
Через разные модели/версии в одном сервере, управление трафиком внешними средствами |
Встроенные механизмы (KServe/Seldon) |
| Примерная стоимость (2026, на 10M инференсов/мес на NVIDIA H200/B200 GPU) |
$500 - $2000 (зависит от оптимизации и выбора инстанса) |
$400 - $1800 (за счет лучшей утилизации) |
$300 - $1500 (оптимальное использование GPU, высокая пропускная способность) |
$600 - $2500 (дополнительные накладные расходы Kubernetes, но с лучшей автоматизацией) |
Примечание: Указанные стоимости являются оценочными для 2026 года и могут варьироваться в зависимости от облачного провайдера, региона, типа инстанса, объема данных и сложности моделей. Они включают в себя только стоимость GPU-инстансов, без учета стоимости CPU, хранилища, сети и других сервисов.
Детальный обзор каждого пункта/варианта
Теперь углубимся в каждый из подходов, представленных в сравнительной таблице, чтобы понять их особенности, преимущества и недостатки, а также сценарии применения.
1. "Сырой" API (FastAPI + PyTorch/TensorFlow/JAX)
Этот подход предполагает создание собственного HTTP API-сервиса с использованием легковесных веб-фреймворков, таких как FastAPI (для Python), Express.js (для Node.js) или Gin (для Go), который напрямую загружает и запускает модель. Модель обычно обернута в PyTorch, TensorFlow или JAX.
Плюсы:
- Полный контроль: Вы имеете полный контроль над каждым аспектом развертывания, от обработки запросов до загрузки модели и логики инференса. Это позволяет реализовать любую специфическую логику.
- Простота для начала: Для простых, небольших моделей, особенно на старте проекта, это самый быстрый способ вывести модель в production, так как не требуется изучения сложных фреймворков инференса.
- Гибкость фреймворков: Поддерживает абсолютно любой ML-фреймворк или библиотеку, которую можно запустить в вашей среде.
- Низкие начальные накладные расходы: Нет необходимости в дополнительных зависимостях, кроме самого фреймворка ML и веб-сервера.
Минусы:
- Отсутствие оптимизаций "из коробки": Динамический батчинг, параллелизм моделей, эффективное управление памятью GPU, мульти-GPU инференс — все это придется реализовывать вручную, что требует значительных усилий и экспертных знаний.
- Сложность масштабирования: Масштабирование становится сложным, так как нет встроенных механизмов для оптимального использования GPU. Часто приводит к низкой утилизации дорогих GPU-ресурсов.
- Высокая задержка и низкая пропускная способность: Без продвинутых техник, таких как динамический батчинг, каждая модель обрабатывает запросы последовательно или с неоптимальным размером пакета, что увеличивает задержку и снижает общую пропускную способность.
- Отсутствие стандартизации: Каждая модель может требовать своего уникального сервиса, что приводит к "зоопарку" и усложняет управление и мониторинг.
Для кого подходит:
Этот подход идеален для стартапов на ранних стадиях, когда нужно быстро протестировать гипотезу с одной или двумя простыми моделями, не требующими экстремальной производительности. Также подходит для очень специфических задач, где стандартные серверы инференса не могут обеспечить необходимую кастомизацию, и команда готова инвестировать в разработку собственных оптимизаций. Однако, как только нагрузка растет или моделей становится больше, необходимо переходить к более специализированным решениям.
2. ONNX Runtime Inference Server
ONNX (Open Neural Network Exchange) Runtime — это кросс-платформенный акселератор инференса, разработанный Microsoft, который поддерживает модели в формате ONNX. ONNX Runtime Inference Server предоставляет готовую обертку для обслуживания таких моделей.
Плюсы:
- Высокая производительность: ONNX Runtime сам по себе очень оптимизирован и может обеспечить низкую задержку и высокую пропускную способность, особенно для CPU. На GPU он также хорошо работает, используя CUDA.
- Кросс-платформенность: Модели в формате ONNX могут быть запущены на различных устройствах и операционных системах, что обеспечивает гибкость развертывания.
- Поддержка множества фреймворков: Модели из PyTorch, TensorFlow, Keras, Scikit-learn и других фреймворков могут быть конвертированы в ONNX формат.
- Легкость развертывания: Сервер относительно прост в настройке и использовании, если у вас уже есть модели в формате ONNX.
- Эффективное использование ресурсов: ONNX Runtime включает в себя различные оптимизации, такие как графовые преобразования и выбор оптимальных операторов, что способствует эффективному использованию как CPU, так и GPU.
Минусы:
- Требуется конвертация в ONNX: Не все модели идеально конвертируются в ONNX, и процесс конвертации может быть трудоемким, особенно для сложных или кастомных операций.
- Меньше глубоких GPU-оптимизаций: Хотя ONNX Runtime поддерживает GPU, он может не достигать того же уровня глубоких оптимизаций (например, TensorRT), что специализированные серверы инференса, такие как Triton, особенно для самых требовательных сценариев.
- Ограниченные возможности для сложных сценариев: Для мультимодельного инференса, ансамблей моделей или динамической загрузки/выгрузки моделей его возможности могут быть менее развитыми по сравнению с Triton.
- Отсутствие динамического батчинга: Хотя ONNX Runtime поддерживает статический батчинг, динамический батчинг, который автоматически объединяет запросы для максимальной утилизации GPU, отсутствует или реализован менее эффективно, чем в Triton.
Для кого подходит:
ONNX Runtime Inference Server отлично подходит для проектов, где уже используется ONNX для унификации моделей, или где необходима высокая производительность на различных аппаратных платформах (включая edge-устройства). Это хороший выбор для замены "сырого" API, когда требуется более высокий уровень оптимизации без сложности Triton, особенно если модели не требуют максимально возможной производительности GPU.
3. NVIDIA Triton Inference Server
NVIDIA Triton Inference Server (ранее TensorRT Inference Server) — это высокопроизводительный, открытый сервер инференса, разработанный NVIDIA для развертывания моделей машинного обучения в production. Он предназначен для максимального использования GPU-ресурсов, обеспечивая при этом низкую задержку и высокую пропускную способность.
Плюсы:
- Максимальная производительность GPU: Triton разработан NVIDIA и глубоко интегрирован с CUDA, TensorRT и другими низкоуровневыми оптимизациями. Он предлагает динамический батчинг, параллелизм моделей и запросов, а также мульти-GPU инференс, что позволяет достичь беспрецедентной утилизации GPU.
- Широкая поддержка фреймворков: Поддерживает TensorFlow, PyTorch, ONNX, TensorRT, OpenVINO, Scikit-learn, XGBoost и имеет возможность расширения с помощью кастомных бэкендов.
- Гибкость конфигурации: Позволяет тонко настраивать поведение сервера для каждой модели, включая размер пакета, количество инстансов модели, политики планирования и управление памятью.
- Мультимодельный инференс: Способен одновременно обслуживать множество моделей, эффективно распределяя ресурсы GPU между ними.
- Динамическая загрузка/выгрузка моделей: Позволяет обновлять модели без перезапуска сервера, что критически важно для production.
- Встроенные метрики: Предоставляет обширные метрики Prometheus для мониторинга производительности и использования ресурсов.
Минусы:
- Кривая обучения: Настройка Triton может быть сложной, особенно для новых пользователей, из-за обилия опций и необходимости понимания концепций, таких как бэкенды, модели-репозитории и политики планирования.
- Требования к инфраструктуре: Для полной реализации потенциала Triton часто требуется развертывание в Kubernetes, что добавляет свою сложность.
- Зависимость от NVIDIA: Хотя есть поддержка CPU и других GPU, максимальная производительность достигается на оборудовании NVIDIA, что может быть ограничением для некоторых проектов.
- Накладные расходы на CPU: Для очень большого количества моделей или сложного планирования, Triton может потреблять значительные ресурсы CPU.
Для кого подходит:
Triton Inference Server является идеальным выбором для компаний, которые работают с высоконагруженными AI-приложениями, требующими максимальной производительности, низкой задержки и высокой пропускной способности. Это включает крупные SaaS-проекты, проекты в области автономного транспорта, компьютерного зрения, обработки естественного языка в реальном времени, а также для любого сценария, где экономическая эффективность использования GPU является приоритетом.
4. KServe / Seldon Core (на Kubernetes)
KServe (ранее KFServing) и Seldon Core — это фреймворки для развертывания моделей машинного обучения на Kubernetes. Они предоставляют высокоуровневые abstractions для обслуживания моделей, включая автомасштабирование, версионирование, A/B-тестирование и канареечные развертывания. Под капотом они могут использовать другие серверы инференса, такие как Triton, TensorFlow Serving, PyTorch Serve или ONNX Runtime Server.
Плюсы:
- Мощные возможности MLOps: Предоставляют комплексные функции для управления жизненным циклом моделей, включая версионирование, A/B-тестирование, канареечные развертывания и автоматическое масштабирование.
- Автоматическое масштабирование: Автоматически масштабируют инстансы модели в зависимости от нагрузки, включая масштабирование до нуля (scale-to-zero) для экономии ресурсов в периоды простоя.
- Стандартизация развертывания: Унифицируют процесс развертывания ML-моделей в Kubernetes, независимо от используемого фреймворка или сервера инференса.
- Высокая доступность и отказоустойчивость: Используют встроенные механизмы Kubernetes для обеспечения высокой доступности и самовосстановления.
- Интеграция с экосистемой Kubernetes: Легко интегрируются с другими сервисами Kubernetes, такими как Istio (для маршрутизации трафика) и Prometheus/Grafana (для мониторинга).
Минусы:
- Высокая сложность: Требуют глубоких знаний Kubernetes и смежных технологий. Развертывание и управление такой инфраструктурой может быть очень сложным и ресурсоемким.
- Накладные расходы Kubernetes: Сама по себе платформа Kubernetes и ее компоненты (control plane, Kube-proxy, Ingress-контроллеры) добавляют накладные расходы на CPU, память и сеть.
- Дополнительный слой абстракции: Хотя абстракция удобна, она может скрывать детали низкоуровневой оптимизации, что затрудняет тонкую настройку производительности.
- Задержка при "холодном старте": При масштабировании до нуля, первый запрос к "холодной" модели может иметь значительно более высокую задержку из-за времени на запуск нового пода.
Для кого подходит:
KServe и Seldon Core идеально подходят для крупных организаций и команд, которые уже активно используют Kubernetes для своей инфраструктуры и имеют опыт работы с ней. Они незаменимы для MLOps-команд, управляющих большим количеством моделей, требующих сложных стратегий развертывания (A/B, canary) и автоматического масштабирования. Это решение для тех, кто готов инвестировать в сложную инфраструктуру ради высокой автоматизации и надежности на масштабе.
Практические советы и рекомендации по оптимизации инференса с Triton Inference Server
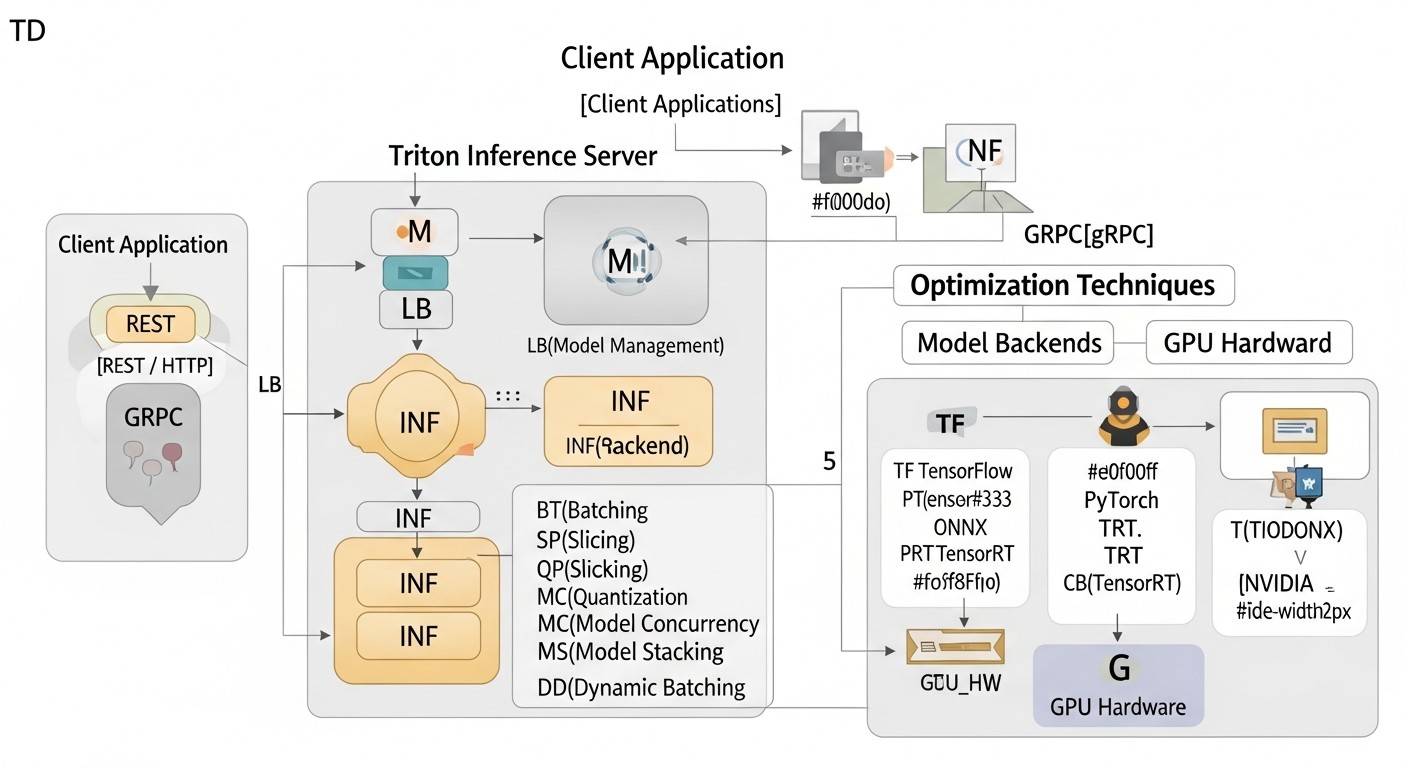 Схема: Практические советы и рекомендации по оптимизации инференса с Triton Inference Server
Схема: Практические советы и рекомендации по оптимизации инференса с Triton Inference Server
В этом разделе мы сфокусируемся на конкретных шагах и конфигурациях, которые помогут вам достичь максимальной производительности и эффективности при использовании Triton Inference Server.
1. Выбор и оптимизация GPU-оборудования (2026 год)
Правильный выбор GPU является фундаментальным. В 2026 году рынок предлагает следующие ключевые опции:
- NVIDIA Blackwell (B200/GB200): Эти GPU являются флагманами для AI, предлагая беспрецедентную вычислительную мощность, особенно для FP8 и FP16 вычислений. Они идеально подходят для самых требовательных и больших моделей.
- NVIDIA H200/H100: Предыдущее поколение Hopper, все еще очень мощные и экономически выгодные для многих задач. H200 с увеличенной памятью (141 ГБ HBM3e) особенно хорош для больших моделей.
- AMD Instinct MI400-серия: Конкурирующие решения от AMD, которые могут предложить лучшую стоимость/производительность в некоторых сценариях, особенно если ваша экосистема уже ориентирована на ROCm.
- NVIDIA L40S/L4: Для более экономичных или менее требовательных сценариев, где не нужна экстремальная производительность HBM-памяти, но важна плотность и энергоэффективность.
Рекомендации:
- Для моделей, требующих максимальной пропускной способности и минимальной задержки, особенно для LLM и мультимодальных моделей, инвестируйте в NVIDIA Blackwell B200/GB200. Они предлагают специализированные блоки для FP8 и FP16, а также улучшенную межсоединение NVLink.
- Для больших моделей (LLM) с умеренной нагрузкой, где важен объем памяти, NVIDIA H200 будет оптимальным выбором.
- Для бюджетных или менее требовательных задач, рассмотрите NVIDIA L40S или L4, которые предлагают отличное соотношение цена/производительность для инференса.
- Используйте NVLink: Если вы развертываете несколько GPU на одном сервере, убедитесь, что они соединены через NVLink. Это значительно ускорит передачу данных между GPU и позволит эффективнее использовать их в мульти-GPU конфигурациях Triton.
2. Оптимизация моделей для инференса
Самый мощный сервер инференса не поможет, если модель не оптимизирована.
- Квантизация (Quantization):
Переход от FP32 к FP16 (половинная точность), INT8 (целочисленная точность) или даже FP8 (в Blackwell GPU) значительно сокращает размер модели и объем вычислений, улучшая задержку и пропускную способность. Для LLM, 4-битная квантизация (GPTQ, AWQ) становится стандартом.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from accelerate import init_empty_weights, load_checkpoint_and_dispatch
from optimum.gptq import GPTQQuantizer, load_quantized_model_from_config
# Пример квантизации для LLM (GPTQ)
model_id = "meta-llama/Llama-2-7b-hf"
quantizer = GPTQQuantizer(bits=4, dataset="wikitext2", model_seqlen=2048)
model_quant = quantizer.quantize_model(model_id, save_dir="llama-2-7b-4bit-gptq")
# Или использование уже квантованной модели
model = load_quantized_model_from_config("llama-2-7b-4bit-gptq")
Рекомендация: Всегда стремитесь к максимальной агрессивной квантизации (INT8, FP8, 4-bit), которая не приводит к неприемлемой деградации качества модели. Для этого используйте методы QAT (Quantization Aware Training) или PTQ (Post-Training Quantization).
- Компиляция с TensorRT:
NVIDIA TensorRT — это SDK для высокопроизводительного инференса, который оптимизирует нейронные сети для GPU NVIDIA. Он выполняет графовые оптимизации, выбирает оптимальные ядра CUDA и может автоматически квантовать модели. Triton имеет встроенную поддержку TensorRT бэкенда.
# Пример конфигурации модели для Triton с TensorRT бэкендом
# model.json в директории модели:
# {
# "name": "my_tensorrt_model",
# "platform": "tensorrt_plan", # или tensorrt_onnx
# "input": [ ... ],
# "output": [ ... ],
# "default_model_filename": "model.plan"
# }
# Конвертация ONNX в TensorRT PLAN
trtexec --onnx=model.onnx --saveEngine=model.plan --fp16 # или --int8
Рекомендация: Для всех моделей на GPU NVIDIA, где это возможно, конвертируйте их в TensorRT PLAN-файлы. Это даст наибольший прирост производительности. Используйте trtexec для компиляции и тестирования.
- ONNX:
Конвертация моделей в ONNX-формат и дальнейшая оптимизация с помощью ONNX Runtime или TensorRT (через ONNX-TensorRT бэкенд в Triton) также значительно улучшает производительность.
3. Конфигурация Triton Inference Server
Ключевые параметры конфигурации, влияющие на производительность:
- Динамический батчинг (Dynamic Batching):
Позволяет Triton объединять несколько входящих запросов в один пакет для инференса на GPU. Это значительно увеличивает утилизацию GPU, так как GPU более эффективно обрабатывают большие пакеты данных. Настраивается в config.pbtxt модели.
# config.pbtxt для модели
dynamic_batching {
max_queue_delay_microseconds: 100000 # Максимальная задержка очереди в 100 мс
preferred_batch_size: [ 4, 8, 16 ] # Предпочтительные размеры пакетов
max_batch_size: 32 # Максимальный размер пакета
}
Рекомендация: Экспериментируйте с max_queue_delay_microseconds и preferred_batch_size. Слишком большая задержка увеличит latency, слишком маленькая — снизит throughput. Оптимальные значения зависят от модели и нагрузки.
- Параллелизм моделей (Instance Groups):
Позволяет запускать несколько копий (инстансов) одной модели на одном или нескольких GPU. Это полезно для увеличения пропускной способности, особенно если один инстанс модели не может полностью загрузить GPU.
# config.pbtxt для модели
instance_group [
{
kind: KIND_GPU
count: 2 # Запустить 2 инстанса модели на каждом GPU
gpus: [ 0, 1 ] # Использовать GPU 0 и 1
}
]
Рекомендация: Начинайте с count: 1. Если утилизация GPU низкая, увеличивайте count, пока не достигнете 90%+ утилизации или не столкнетесь с деградацией задержки.
- Планировщики (Schedulers):
Triton предлагает различные планировщики для управления запросами. Default (Sequence Batcher) подходит для большинства случаев. Для stateful моделей (RNN, LLM с историей) используйте Sequence Batcher.
# config.pbtxt для stateful модели
sequence_batching {
max_sequence_idle_microseconds: 5000000 # 5 секунд
state_input {
name: "STATE_IN"
data_type: TYPE_FP32
dims: [ 1024 ]
}
state_output {
name: "STATE_OUT"
data_type: TYPE_FP32
dims: [ 1024 ]
}
}
Рекомендация: Внимательно настраивайте max_sequence_idle_microseconds для stateful моделей, чтобы балансировать между сохранением контекста и освобождением ресурсов.
- Кэширование моделей:
Triton поддерживает кэширование моделей в памяти GPU, что позволяет быстро переключаться между ними без повторной загрузки. Для больших LLM, которые занимают всю память GPU, это может быть неактуально, но для небольших моделей, используемых в ансамблях, это критично.
4. Развертывание в Kubernetes (с KServe/Seldon Core)
Для Production-среды Kubernetes является стандартом. Интеграция Triton с KServe или Seldon Core упрощает управление.
- Использование Helm-чартов:
Для быстрого развертывания Triton используйте официальный Helm-чарт NVIDIA.
helm repo add nvdp https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install triton nvdp/triton-inference-server \
--namespace triton \
--create-namespace \
--set replicaCount=1 \
--set modelRepository.pv.enabled=true \
--set modelRepository.pv.size=50Gi \
--set service.type=LoadBalancer \
--set gpu.enabled=true \
--set nvidia.driver.enabled=false # Предполагаем, что драйверы уже установлены
- Интеграция с KServe:
KServe позволяет развертывать Triton как один из поддерживаемых рантаймов. Пример KServe InferenceService для Triton:
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "my-triton-model"
spec:
predictor:
triton:
protocolVersion: v2 # Или v1
storageUri: "s3://my-model-bucket/models/my-triton-model"
resources:
limits:
nvidia.com/gpu: "1" # Запросить 1 GPU
memory: "32Gi"
requests:
nvidia.com/gpu: "1"
memory: "32Gi"
# Можно также указать image: "nvcr.io/nvidia/tritonserver:23.09-py3"
Рекомендация: Используйте KServe для абстракции и автоматизации. Убедитесь, что у вас установлен NVIDIA GPU Operator в Kubernetes для корректной работы GPU.
5. Мониторинг и профилирование
Без мониторинга невозможно понять, что происходит с вашим инференсом.
- Prometheus и Grafana:
Triton предоставляет метрики в формате Prometheus. Настройте Prometheus для сбора этих метрик и Grafana для визуализации. Ключевые метрики:
nv_gpu_utilization: Утилизация GPUnv_gpu_memory_used_bytes: Использование памяти GPUnv_inference_request_duration_us: Задержка запросовnv_inference_request_count: Количество запросовnv_inference_queue_duration_us: Время в очереди динамического батчинга
- NVIDIA DCGM Exporter:
Для более детального мониторинга GPU используйте DCGM Exporter, который предоставляет метрики GPU на уровне оборудования.
# Пример развертывания DCGM Exporter в Kubernetes
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/gpu-operator/master/deployments/cluster-monitoring/dcgm-exporter.yaml
- Профилирование с Nsight Systems/Nsight Compute:
Для глубокого анализа производительности отдельных моделей или бэкендов используйте инструменты NVIDIA Nsight Systems и Nsight Compute. Они помогают выявить узкие места на уровне ядер CUDA, операций с памятью и межпроцессорного взаимодействия.
# Запуск Triton с Nsight Systems для профилирования
nsys profile --output my_triton_profile --duration 60 \
tritonserver --model-repository=/models
Рекомендация: Всегда имейте настроенный стек мониторинга. Используйте алерты для критических метрик (например, высокая задержка, низкая утилизация GPU, ошибки). Регулярно проводите профилирование для выявления скрытых узких мест.
Типичные ошибки при развертывании высокопроизводительного AI/ML инференса и как их избежать
 Схема: Типичные ошибки при развертывании высокопроизводительного AI/ML инференса и как их избежать
Схема: Типичные ошибки при развертывании высокопроизводительного AI/ML инференса и как их избежать
Даже опытные команды сталкиваются с подводными камнями при оптимизации инференса. Знание этих ошибок поможет избежать дорогостоящих проблем.
1. Игнорирование оптимизации моделей до деплоя
Ошибка: Развертывание "сырых" моделей (например, в FP32 PyTorch или TensorFlow) без какой-либо оптимизации (квантизация, TensorRT-компиляция). Многие считают, что мощный GPU и Triton сами по себе решат все проблемы.
Последствия: Крайне низкая производительность, высокая задержка, огромные затраты на GPU, так как модель не использует его эффективно. GPU может быть загружен на 20-30% при полной вычислительной мощности.
Как избежать:
- Всегда начинайте с оптимизации модели. Квантизация (INT8, FP8, 4-bit) и компиляция (TensorRT, OpenVINO) должны быть первыми шагами.
- Используйте профилировщики (Nsight Systems) для оценки производительности модели до ее загрузки в Triton.
- Включите оптимизацию в ваш MLOps-пайплайн, чтобы каждая новая версия модели автоматически проходила этап оптимизации.
2. Неправильная настройка динамического батчинга
Ошибка: Установка слишком маленького max_queue_delay_microseconds или слишком большого max_batch_size без учета характеристик модели и ожидаемой нагрузки.
Последствия:
- Слишком маленький
max_queue_delay_microseconds: Низкая утилизация GPU, так как Triton не успевает собрать достаточно запросов в пакет, что приводит к обработке маленьких пакетов.
- Слишком большой
max_batch_size: Увеличение задержки для отдельных запросов, которые ждут, пока соберётся полный пакет. Также может привести к ошибкам OOM (Out Of Memory) на GPU.
Как избежать:
- Тщательно тестируйте динамический батчинг под реалистичной нагруззокой. Начните с небольших
preferred_batch_size и max_batch_size, постепенно увеличивая их.
- Мониторьте метрики
nv_inference_queue_duration_us и nv_inference_compute_duration_us, а также утилизацию GPU. Ищите баланс между задержкой и пропускной способностью.
- Используйте
concurrency_limit в config.pbtxt, чтобы предотвратить перегрузку GPU и избежать OOM.
3. Отсутствие адекватного мониторинга
Ошибка: Развертывание Triton без настроенного Prometheus/Grafana или других систем мониторинга.
Последствия: Невозможность выявить узкие места производительности, понять причины деградации сервиса, оптимизировать использование ресурсов или отреагировать на сбои. Вы будете "летать вслепую".
Как избежать:
- С самого начала внедрите стандартный стек мониторинга (Prometheus, Grafana).
- Используйте NVIDIA DCGM Exporter для глубокого мониторинга GPU.
- Настройте алерты для ключевых метрик: утилизация GPU, задержка запросов, количество ошибок.
4. Неправильное управление памятью GPU (OOM-ошибки)
Ошибка: Загрузка слишком большого количества моделей или инстансов моделей на один GPU, что приводит к переполнению памяти GPU.
Последствия: Сбои инференса, перезапуски Triton-подов, нестабильная работа сервиса, потеря данных запросов.
Как избежать:
- Точно знайте объем памяти, потребляемой каждой моделью. Используйте
nvidia-smi или DCGM для мониторинга.
- Используйте
instance_group с параметром count для контроля количества инстансов модели на GPU.
- В Kubernetes, устанавливайте адекватные
resources.limits.nvidia.com/gpu и resources.limits.memory для подов Triton.
- Рассмотрите возможность разделения больших моделей на несколько GPU (model parallelism) или использования техник, таких как offloading слоев на CPU, если это возможно.
5. Недооценка сложности развертывания в Kubernetes
Ошибка: Предположение, что развертывание Triton в Kubernetes будет таким же простым, как запуск Docker-контейнера.
Последствия: Длительные задержки в деплое, проблемы с сетевой конфигурацией, доступом к хранилищу моделей, интеграцией с GPU-драйверами, масштабированием и мониторингом. Неэффективное использование ресурсов кластера.
Как избежать:
- Инвестируйте в обучение команды Kubernetes.
- Используйте официальные Helm-чарты NVIDIA для Triton и NVIDIA GPU Operator для управления GPU-драйверами.
- Настройте Persistent Volumes для Model Repository.
- Настройте Ingress-контроллер и Service Mesh (например, Istio) для управления трафиком и A/B-тестирования.
6. Игнорирование версионирования моделей и A/B-тестирования
Ошибка: Прямая замена старой модели новой версией без тестирования на части трафика.
Последствия: Деградация качества инференса, обнаруженная только после полного развертывания, что может привести к значительным потерям для бизнеса и репутационным рискам.
Как избежать:
- Используйте возможности Triton по версионированию моделей (разные поддиректории в репозитории).
- Применяйте Kubernetes-операторы, такие как KServe или Seldon Core, которые предоставляют встроенные механизмы для канареечных развертываний и A/B-тестирования.
- Всегда тестируйте новые версии моделей на небольшом проценте реального трафика перед полным развертыванием.
7. Отсутствие стратегии для "холодного старта" (cold start)
Ошибка: При использовании автомасштабирования до нуля (scale-to-zero) не учитывается время, необходимое для запуска пода и загрузки модели при первом запросе.
Последствия: Очень высокая задержка для первых запросов после периода простоя, что неприемлемо для многих real-time приложений.
Как избежать:
- Используйте предустановленные реплики (min replicas > 0) для критически важных моделей, чтобы избежать холодного старта.
- Для менее критичных моделей, оптимизируйте время загрузки модели (например, с помощью TensorRT, уменьшения размера модели).
- Рассмотрите использование "прогревочных" запросов (warm-up requests) после запуска нового инстанса.
- В KServe, настройте
minReplicas для поддержания минимального количества запущенных подов.
Чеклист для практического применения Triton Inference Server
Этот чеклист поможет вам систематизировать процесс развертывания и оптимизации AI/ML инференса с использованием Triton Inference Server.
- Подготовка модели:
- [ ] Выбран и зафиксирован формат модели (PyTorch, TensorFlow, ONNX).
- [ ] Модель обучена и валидирована на тестовых данных.
- [ ] Определены входные и выходные тензоры модели, их типы данных и размерности.
- Оптимизация модели:
- [ ] Модель квантована (FP16, INT8, FP8, 4-bit) до максимально возможной степени без неприемлемой деградации качества.
- [ ] Модель конвертирована в ONNX формат (если не используется напрямую в PyTorch/TF).
- [ ] Модель скомпилирована с помощью NVIDIA TensorRT (для GPU NVIDIA), если это применимо.
- [ ] Проверена производительность оптимизированной модели локально (например, с
trtexec).
- Выбор оборудования:
- [ ] Определен тип GPU (NVIDIA B200/H200/L40S или AMD MI400), исходя из требований к производительности и бюджета.
- [ ] Если on-premise, обеспечено наличие совместимых драйверов GPU и CUDA.
- [ ] Если в облаке, выбран подходящий GPU-инстанс.
- Настройка Model Repository:
- [ ] Создана структура директорий для моделей (
model_repository/model_name/version_number/).
- [ ] Модели помещены в соответствующие директории.
- [ ] Для каждой модели создан
config.pbtxt с описанием входных/выходных тензоров, бэкенда и других параметров.
- Конфигурация Triton Inference Server:
- [ ] Настроен динамический батчинг (
dynamic_batching) в config.pbtxt для каждой модели.
- [ ] Настроены группы инстансов (
instance_group) для каждой модели, чтобы эффективно использовать GPU.
- [ ] Для stateful моделей настроен
sequence_batching.
- [ ] Выбран соответствующий бэкенд для каждой модели (TensorRT, ONNXRuntime, PyTorch, TensorFlow и т.д.).
- Развертывание Triton (Docker/Kubernetes):
- [ ] Выбран подходящий Docker-образ Triton Server (например,
nvcr.io/nvidia/tritonserver:23.09-py3).
- [ ] Если используется Docker, команда
docker run --gpus all ... настроена корректно.
- [ ] Если используется Kubernetes:
- [ ] Установлен NVIDIA GPU Operator.
- [ ] Используется Helm-чарт для развертывания Triton или KServe/Seldon Core.
- [ ] Настроены Persistent Volumes для Model Repository.
- [ ] Определены
resource requests/limits для GPU и памяти в манифестах подов.
- Настройка сети и доступа:
- [ ] Определены порты для HTTP/gRPC API Triton (8000/8001) и метрик (8002).
- [ ] Настроен Ingress-контроллер (для Kubernetes) или балансировщик нагрузки для доступа к Triton.
- [ ] Обеспечена безопасность: TLS/SSL, аутентификация/авторизация (если требуется).
- Мониторинг и логирование:
- [ ] Настроен Prometheus для сбора метрик Triton и DCGM Exporter.
- [ ] Настроена Grafana для визуализации метрик и создания дашбордов.
- [ ] Настроены алерты для ключевых показателей производительности и ошибок.
- [ ] Настроено централизованное логирование (ELK Stack, Loki) для сбора логов Triton.
- Тестирование производительности:
- [ ] Проведено нагрузочное тестирование с использованием инструментов (Locust, JMeter, K6) для оценки задержки и пропускной способности.
- [ ] Проверена утилизация GPU под нагруззкой.
- [ ] Проведено A/B-тестирование (если применимо) для новых версий моделей.
- Резервное копирование и восстановление:
- [ ] Разработана стратегия резервного копирования Model Repository.
- [ ] Проверена возможность восстановления сервиса после сбоя.
Расчет стоимости и экономика высокопроизводительного инференса на GPU (2026 год)
 Схема: Расчет стоимости и экономика высокопроизводительного инференса на GPU (2026 год)
Схема: Расчет стоимости и экономика высокопроизводительного инференса на GPU (2026 год)
Экономическая эффективность инференса — это не просто стоимость GPU, но и совокупность факторов, включая утилизацию, затраты на инженеров, энергопотребление и потенциальные скрытые расходы. В 2026 году, когда GPU-инфраструктура становится еще дороже и мощнее, оптимизация затрат является критически важной.
Примеры расчетов для разных сценариев (2026 год)
Рассмотрим гипотетические сценарии для оценки стоимости инференса, используя актуальные для 2026 года облачные цены на GPU-инстансы (предполагаем усредненные цены на NVIDIA H200 и Blackwell B200 в крупных облачных провайдерах).
Сценарий 1: Небольшой стартап с умеренной нагрузкой
- Модель: Небольшая CV-модель (например, ResNet-50), оптимизированная (INT8/FP16).
- Требования: 100 запросов в секунду (RPS) в пике, средняя задержка до 50 мс.
- Оборудование: 1x NVIDIA L40S GPU (или эквивалент) в облаке.
- Стоимость L40S: ~$1.50/час (постоянная нагрузка, без скидок).
- Производительность модели на L40S: До 500-800 RPS для FP16/INT8.
- Утилизация GPU: ~15-20% при 100 RPS.
- Расчет:
- Стоимость в месяц: 1.50 $/час 24 часа/день 30 дней/месяц = 1080 $
- Стоимость за 1 млн инференсов: (1080 $ / (100 RPS 3600 сек/час 24 часа/день 30 дней/месяц)) 1,000,000 = (1080 $ / 259,200,000) 1,000,000 = ~4.17 $ за 1 млн инференсов.
Вывод: Даже с умеренной нагрузкой, GPU может быть сильно недоутилизирован. Важно использовать Triton для максимальной загрузки, даже если кажется, что одного GPU слишком много. Здесь, возможно, стоит рассмотреть масштабирование до нуля или использование спотовых инстансов.
Сценарий 2: Средний SaaS-проект с высокой нагрузкой
- Модель: LLM среднего размера (7B-13B параметров), 4-bit квантизация, TensorRT.
- Требования: 500 запросов в секунду (RPS) в пике, средняя задержка до 100 мс.
- Оборудование: 2x NVIDIA H200 GPU инстанса (каждый с 1 GPU) в облаке.
- Стоимость H200: ~$4.50/час за инстанс (постоянная нагрузка).
- Производительность модели на H200: ~300-400 RPS для 4-bit LLM.
- Утилизация GPU: ~70-80% на каждом GPU (с Triton).
- Расчет:
- Стоимость в месяц (2 инстанса): 2 4.50 $/час 24 часа/день 30 дней/месяц = 6480 $
- Общая пропускная способность: 2 350 RPS = 700 RPS (с запасом).
- Стоимость за 1 млн инференсов: (6480 $ / (700 RPS 3600 сек/час 24 часа/день 30 дней/месяц)) 1,000,000 = (6480 $ / 1,814,400,000) 1,000,000 = ~3.57 $ за 1 млн инференсов.
Вывод: Благодаря Triton и оптимизации, утилизация GPU значительно выше, что снижает стоимость за инференс. Масштабирование до 2 GPU позволяет справиться с пиковой нагрузкой.
Сценарий 3: Крупное предприятие с экстремальной нагрузкой и большими моделями
- Модель: SOTA LLM (70B+ параметров), FP8/FP16, TensorRT.
- Требования: 2000 запросов в секунду (RPS) в пике, средняя задержка до 200 мс.
- Оборудование: 4x NVIDIA Blackwell B200 GPU инстанса (каждый с 1 GPU) в облаке.
- Стоимость B200: ~$8.00/час за инстанс (постоянная нагрузка).
- Производительность модели на B200: ~600-700 RPS для FP8 LLM.
- Утилизация GPU: ~85-95% на каждом GPU (с Triton).
- Расчет:
- Стоимость в месяц (4 инстанса): 4 8.00 $/час 24 часа/день 30 дней/месяц = 23040 $
- Общая пропускная способность: 4 650 RPS = 2600 RPS (с запасом).
- Стоимость за 1 млн инференсов: (23040 $ / (2600 RPS 3600 сек/час 24 часа/день 30 дней/месяц)) 1,000,000 = (23040 $ / 6,739,200,000) * 1,000,000 = ~3.42 $ за 1 млн инференсов.
Вывод: Несмотря на высокую стоимость B200, их производительность и оптимизация с Triton позволяют достичь очень низкой стоимости за инференс на больших масштабах, благодаря высокой утилизации и специализированным возможностям FP8.
Скрытые расходы
- Трафик данных: Передача больших объемов данных (входных/выходных тензоров) между клиентом и сервером, а также между регионами облака, может быть дорогостоящей.
- Хранение моделей: Стоимость S3-совместимого хранилища для model repository.
- CPU-ресурсы: Triton потребляет CPU для управления запросами, динамического батчинга и других накладных расходов. Kubernetes, KServe/Seldon Core также требуют значительных CPU-ресурсов.
- Мониторинг и логирование: Стоимость хранения метрик Prometheus и логов.
- Лицензии: Некоторые специализированные инструменты или бэкенды могут требовать лицензий.
- Инженерное время: Самый большой скрытый расход. Время, потраченное на настройку, оптимизацию, отладку и поддержку инфраструктуры инференса.
- Энергопотребление и охлаждение (для on-premise): Значительные расходы для собственных дата-центров.
Как оптимизировать затраты
- Максимальная утилизация GPU:
- Используйте Triton Inference Server с динамическим батчингом и параллелизмом моделей.
- Объединяйте несколько моделей на одном GPU, если это возможно.
- Мониторьте утилизацию GPU и масштабируйте ресурсы в соответствии с ней.
- Агрессивная оптимизация моделей:
- Квантуйте модели до INT8/FP8/4-bit.
- Используйте TensorRT для компиляции.
- Уменьшайте размер моделей, если это не вредит качеству.
- Эффективное масштабирование:
- Используйте автомасштабирование (HPA в Kubernetes) для динамического добавления/удаления GPU-инстансов.
- Рассмотрите масштабирование до нуля (scale-to-zero) для моделей с прерывистой нагрузкой, но учитывайте холодный старт.
- Используйте спотовые/прерываемые инстансы в облаке для некритичных задач или в качестве дополнительной емкости, но будьте готовы к их внезапному отключению.
- Выбор правильного GPU-инстанса:
- Не всегда самый мощный GPU является лучшим выбором. Подбирайте GPU, который соответствует требованиям вашей модели и нагрузке.
- Сравнивайте предложения разных облачных провайдеров, так как цены могут сильно варьироваться.
- Оптимизация сетевого трафика:
- Сжимайте входные и выходные данные.
- Размещайте сервер инференса как можно ближе к клиентам или источникам данных.
- Управление жизненным циклом моделей:
- Регулярно переобучайте и оптимизируйте модели, чтобы они оставались актуальными и эффективными.
- Удаляйте неиспользуемые или устаревшие модели.
Таблица с примерами расчетов для разных сценариев
| Параметр |
Сценарий 1 (Стартап) |
Сценарий 2 (SaaS-проект) |
Сценарий 3 (Предприятие) |
| Тип модели |
CV (ResNet-50) |
LLM (7B-13B) |
LLM (70B+) |
| Оптимизация |
INT8/FP16 |
4-bit Quantization, TensorRT |
FP8/FP16, TensorRT |
| Пиковая нагрузка (RPS) |
100 |
500 |
2000 |
| Требуемая задержка (мс) |
50 |
100 |
200 |
| GPU-инстанс (2026) |
1x L40S |
2x H200 |
4x B200 |
| Примерная стоимость GPU/час |
$1.50 |
$4.50 (за H200) |
$8.00 (за B200) |
| Месячная стоимость GPU (постоянная) |
$1,080 |
$6,480 |
$23,040 |
| Средняя утилизация GPU |
15-20% |
70-80% |
85-95% |
| Стоимость за 1 млн инференсов |
~$4.17 |
~$3.57 |
~$3.42 |
Кейсы и примеры из реальной практики
 Схема: Кейсы и примеры из реальной практики
Схема: Кейсы и примеры из реальной практики
Теория важна, но реальные кейсы показывают, как принципы применяются на практике и какие результаты можно получить.
Кейс 1: Оптимизация инференса для системы рекомендаций в реальном времени
Компания: Крупный e-commerce ритейлер, обслуживающий миллионы пользователей ежедневно.
Проблема: Существующая система рекомендаций на основе PyTorch-моделей работала медленно. Каждая рекомендация требовала нескольких инференсов, что приводило к задержке в 300-500 мс. Пропускная способность составляла всего около 100 RPS на одном GPU, что требовало большого количества дорогих инстансов. Модели были развернуты как отдельные FastAPI-сервисы.
Решение:
- Консолидация моделей: Все рекомендательные модели были переведены в Triton Inference Server.
- Оптимизация моделей: Каждая модель была квантована до FP16, а затем скомпилирована в TensorRT PLAN-файл.
- Настройка Triton:
- Включен динамический батчинг с
max_queue_delay_microseconds: 50000 (50 мс) и preferred_batch_size: [8, 16, 32].
- Для каждой модели настроено
instance_group с count: 2 на каждый GPU, чтобы максимизировать утилизацию.
- Инфраструктура: Развернуто на Kubernetes с использованием KServe, что позволило настроить автомасштабирование и A/B-тестирование новых версий моделей. Использовались GPU NVIDIA H100.
Результаты:
- Задержка: Снижена до 80-120 мс (p95), что позволило улучшить пользовательский опыт и конверсию.
- Пропускная способность: Увеличена до 1200-1500 RPS на одном H100 GPU (в 12-15 раз по сравнению с исходной).
- Стоимость: Сокращены расходы на GPU-инфраструктуру на 60% за счет значительного увеличения утилизации и уменьшения количества необходимых инстансов.
- Управление: Упрощено управление моделями благодаря KServe и централизованному репозиторию Triton.
Кейс 2: Развертывание мультимодальной LLM для генерации контента
Компания: Стартап в области AI-генерации контента, использующий большую мультимодальную модель (текст-изображение) с 20B параметров.
Проблема: Модель была очень большой и медленной. Загрузка в память занимала несколько минут, а один инференс длился 5-10 секунд на одном GPU. Компания не могла масштабироваться из-за огромных затрат на GPU и низкой пропускной способности. Использовались облачные инстансы с NVIDIA A100.
Решение:
- Выбор оборудования (2026): Переход на инстансы с NVIDIA Blackwell B200 GPU, которые предлагают специализированные ядра для FP8 и увеличенную HBM-память.
- Оптимизация модели:
- Модель была тщательно оптимизирована: применена 8-битная квантизация (FP8) для вычислений и частичная 4-битная для весов.
- Полностью скомпилирована в TensorRT PLAN-файл.
- Настройка Triton:
- Использован TensorRT бэкенд в Triton.
- Динамический батчинг настроен с
max_queue_delay_microseconds: 200000 (200 мс) и preferred_batch_size: [1, 2, 4], так как задержка была менее критичной, чем пропускная способность.
- Использован
model_ensemble для объединения текстового и графического компонентов модели в один пайплайн инференса внутри Triton.
- Настроены
instance_group с count: 1 на каждый B200, так как модель занимала почти всю память GPU.
- Инфраструктура: Развернуто на Kubernetes с использованием Seldon Core для управления развертываниями и мониторинга.
Результаты:
- Время инференса: Снижено с 5-10 секунд до 800-1500 мс на B200 GPU.
- Пропускная способность: Увеличена до 600-700 RPS на одном B200 GPU (по сравнению с 10 RPS на A100).
- Стоимость: Несмотря на более дорогие B200, общая стоимость инференса на единицу контента снизилась на 40% за счет колоссального увеличения пропускной способности и утилизации.
- Масштабирование: Стартап смог обслуживать значительно больше клиентов и расширить свои предложения.
Кейс 3: Инференс для edge-устройств с централизованным управлением
Компания: Производитель умных камер для видеонаблюдения, использующий AI для обнаружения объектов на устройствах.
Проблема: Десятки тысяч камер по всему миру, каждая из которых должна выполнять инференс локально. Обновление моделей было сложным, мониторинг производительности на edge-устройствах — практически невозможным. Использовались легковесные модели, развернутые с ONNX Runtime.
Решение:
- Централизованный репозиторий моделей: Все модели хранятся в Triton Model Repository, доступном через облако.
- Оптимизация для edge: Модели были сильно квантованы (INT8) и конвертированы в ONNX. Для некоторых устройств использовался OpenVINO бэкенд Triton.
- Triton на Edge: На каждом edge-устройстве был развернут легковесный Triton Inference Server (без GPU, используя CPU или встроенные NPU/VPU, поддерживающие OpenVINO).
- Удаленное управление: Triton на edge-устройствах настроен на периодическую синхронизацию с центральным Model Repository. Это позволило удаленно обновлять модели и их конфигурации.
- Мониторинг: Triton на edge-устройствах настроен для отправки ключевых метрик (RPS, задержка, ошибки) в централизованную систему мониторинга (Loki/Grafana), что дало беспрецедентный обзор производительности.
Результаты:
- Обновление моделей: Время развертывания новой модели сократилось с недель до нескольких часов.
- Производительность: Стабильная и предсказуемая производительность на edge-устройствах благодаря оптимизации и Triton.
- Видимость: Получен полный контроль и мониторинг над производительностью AI на десятках тысяч устройств.
- Масштабируемость: Легкость добавления новых устройств и моделей в экосистему.
Troubleshooting: решение типичных проблем при работе с Triton Inference Server
 Схема: Troubleshooting: решение типичных проблем при работе с Triton Inference Server
Схема: Troubleshooting: решение типичных проблем при работе с Triton Inference Server
Развертывание высокопроизводительного инференса — сложная задача, и проблемы неизбежны. Ниже представлены типичные проблемы, с которыми можно столкнуться, и пути их решения.
1. Проблема: Triton не запускается или не загружает модели
Симптомы: Контейнер Triton завершается с ошибкой, или в логах Triton видно, что модели не загружаются (failed to load model).
Диагностические команды:
docker logs <container_id> или kubectl logs <pod_name> -n <namespace>- Проверьте статус готовности Triton:
curl -v localhost:8000/v2/health/ready
Возможные причины и решения:
- Неправильный путь к Model Repository: Убедитесь, что
--model-repository указывает на корректный путь, и Triton имеет права доступа к нему.
- Ошибки в
config.pbtxt: Синтаксические ошибки, неправильные типы данных, размерности, несуществующие бэкенды. Внимательно проверьте конфигурацию модели.
- Несовместимость версии бэкенда: Модель или бэкенд требуют другой версии фреймворка (TensorFlow, PyTorch), чем та, что установлена в Docker-образе Triton. Используйте соответствующие образы (например,
tritonserver:23.09-tf2-py3).
- Отсутствие GPU-драйверов или CUDA: Если Triton запускается на GPU, убедитесь, что драйверы NVIDIA и CUDA установлены и корректно настроены. В Docker используйте флаг
--gpus all. В Kubernetes установите NVIDIA GPU Operator.
- Нехватка памяти (RAM/GPU): Модель слишком большая для доступной памяти. Проверьте логи на ошибки OOM. Уменьшите количество инстансов модели или используйте GPU с большим объемом памяти.
2. Проблема: Низкая производительность (высокая задержка, низкая пропускная способность)
Симптомы: Запросы обрабатываются медленно, утилизация GPU низкая, даже под нагрузкой.
Диагностические команды:
- Мониторинг метрик Prometheus/Grafana (
nv_gpu_utilization, nv_inference_request_duration_us, nv_inference_queue_duration_us).
- Используйте
perf_analyzer для нагрузочного тестирования.
- Профилирование с Nsight Systems.
Возможные причины и решения:
- Неоптимизированная модель: Самая частая причина. Убедитесь, что модель квантована (INT8/FP16/FP8) и скомпилирована с TensorRT (если это GPU NVIDIA).
- Неправильный динамический батчинг:
- Если
nv_inference_queue_duration_us высок, а nv_gpu_utilization низок: Увеличьте max_queue_delay_microseconds, чтобы Triton успевал собрать пакеты.
- Если
nv_inference_request_duration_us высок, но nv_inference_queue_duration_us низок: Возможно, модель плохо оптимизирована, или max_batch_size слишком велик для допустимой задержки.
- Недостаточное количество инстансов модели: Если один инстанс не загружает GPU полностью, увеличьте
count в instance_group.
- Бутылочное горлышко CPU: Triton сам по себе или процесс подготовки входных данных может потреблять много CPU. Мониторьте CPU-утилизацию. Выделите больше CPU-ресурсов для пода Triton.
- Низкая пропускная способность I/O: Модели загружаются медленно из-за медленного хранилища. Используйте более быстрые диски или кэширование.
3. Проблема: Ошибки Out Of Memory (OOM) на GPU
Симптомы: Triton-поды перезапускаются с ошибками, связанными с нехваткой памяти GPU.
Диагностические команды:
docker logs или kubectl logs, ищите сообщения CUDA out of memory или OOM.- Мониторинг
nv_gpu_memory_used_bytes в Grafana.
Возможные причины и решения:
- Слишком много инстансов модели: Уменьшите
count в instance_group.
- Слишком большой
max_batch_size: Уменьшите максимальный размер пакета.
- Большая модель: Переключитесь на GPU с большим объемом памяти (например, H200 вместо H100).
- Неоптимизированная модель: Квантизация значительно снижает потребление памяти.
- Фрагментация памяти GPU: Иногда перезапуск Triton может помочь, но это временное решение.
- Некорректные лимиты в Kubernetes: Убедитесь, что
resources.limits.nvidia.com/gpu и resources.limits.memory соответствуют реальным потребностям.
4. Проблема: Проблемы с сетевым доступом к Triton
Симптомы: Клиенты не могут подключиться к Triton, тайм-ауты запросов.
Диагностические команды:
ping, telnet или nc на IP/порт Triton.kubectl describe service <triton_service>, kubectl describe ingress <triton_ingress>.- Проверьте логи Ingress-контроллера.
Возможные причины и решения:
- Неправильная конфигурация Ingress/Service: Убедитесь, что Kubernetes Service и Ingress-ресурсы правильно маршрутизируют трафик на поды Triton.
- Фаервол: Проверьте правила фаервола на сервере, в облачной VPC или на уровне Kubernetes NetworkPolicy.
- Проблемы DNS: Убедитесь, что доменное имя разрешается в корректный IP-адрес.
- Неправильный порт: Убедитесь, что клиент подключается к правильному порту (8000 для HTTP, 8001 для gRPC).
5. Проблема: Несоответствие входных/выходных данных модели
Симптомы: Ошибки типа Input '...' has unexpected shape/data type или Output '...' has unexpected shape/data type.
Диагностические команды:
- Проверьте логи Triton.
- Используйте Triton client для отправки тестовых запросов и проверки ошибок.
Возможные причины и решения:
- Несоответствие
config.pbtxt: Типы данных (TYPE_FP32, TYPE_INT32), размерности (dims) или имена входных/выходных тензоров в config.pbtxt не соответствуют фактическим требованиям модели.
- Неправильная подготовка данных на клиенте: Клиент отправляет данные в неправильном формате или размере.
- Различия между фреймворками: При конвертации модели (например, из PyTorch в ONNX) могли измениться имена или порядок тензоров.
Когда обращаться в поддержку
- Если вы столкнулись с ошибками, которые кажутся связанными с внутренними механизмами Triton или CUDA, а не с вашей конфигурацией или моделью.
- Если вы обнаружили потенциальный баг в Triton или TensorRT.
- Если вы не можете решить проблему после тщательного изучения документации, форумов и использования диагностических инструментов.
Для обращения в поддержку используйте форумы NVIDIA Developer, репозиторий Triton на GitHub (для отчетов об ошибках) или официальные каналы поддержки NVIDIA, если у вас есть соответствующая подписка.
FAQ: Часто задаваемые вопросы по Triton Inference Server
1. Что такое Triton Inference Server и зачем он нужен?
Triton Inference Server — это высокопроизводительный, открытый сервер инференса, разработанный NVIDIA. Он предназначен для эффективного развертывания моделей машинного обучения на GPU (и CPU) в production-средах. Triton решает проблемы низкой утилизации GPU, высокой задержки и низкой пропускной способности, предлагая такие функции, как динамический батчинг, параллелизм моделей, мульти-GPU инференс и поддержку множества ML-фреймворков. Он позволяет максимально эффективно использовать дорогие GPU-ресурсы.
2. Какие ML-фреймворки поддерживает Triton?
Triton поддерживает широкий спектр популярных ML-фреймворков и форматов, включая TensorFlow (SavedModel, GraphDef), PyTorch (TorchScript), ONNX, NVIDIA TensorRT, OpenVINO, Scikit-learn, XGBoost и даже кастомные бэкенды. Это позволяет командам использовать различные модели в одном сервере инференса, унифицируя процесс развертывания.
3. В чем главное отличие Triton от простого FastAPI-сервиса с моделью?
Главное отличие в глубокой оптимизации для GPU и продвинутых функциях управления инференсом. FastAPI-сервис требует ручной реализации динамического батчинга, параллелизма и управления памятью GPU, что очень сложно. Triton предоставляет эти функции "из коробки", максимизируя утилизацию GPU, снижая задержку и увеличивая пропускную способность без значительных усилий со стороны разработчика.
4. Что такое динамический батчинг и как его настроить?
Динамический батчинг — это механизм Triton, который объединяет несколько входящих запросов в один "пакет" для обработки на GPU. GPU гораздо эффективнее обрабатывают большие пакеты данных. Настраивается это в файле config.pbtxt модели с помощью секции dynamic_batching, где вы указываете max_queue_delay_microseconds (максимальное время ожидания запроса в очереди) и preferred_batch_size (предпочтительные размеры пакетов).
5. Как Triton помогает сэкономить деньги?
Triton экономит деньги за счет максимальной утилизации дорогих GPU. Вместо того чтобы платить за простаивающие GPU, Triton позволяет выжимать из них максимум производительности, обрабатывая больше запросов в секунду на одном и том же оборудовании. Это сокращает количество необходимых GPU-инстансов, снижая облачные расходы и затраты на электроэнергию (для on-premise).
6. Нужен ли Kubernetes для работы с Triton?
Нет, Triton можно запустить как обычный Docker-контейнер на любом сервере с GPU. Однако для production-среды, где важны автомасштабирование, высокая доступность, версионирование моделей и централизованное управление, Kubernetes становится де-факто стандартом. Интеграция Triton с Kubernetes через KServe или Seldon Core значительно упрощает MLOps.
7. Что такое TensorRT и почему он важен для Triton?
TensorRT — это SDK от NVIDIA для высокопроизводительного инференса, который оптимизирует нейронные сети для GPU NVIDIA. Он выполняет графовые оптимизации, выбирает оптимальные ядра CUDA и может квантовать модели. Triton имеет нативную поддержку TensorRT бэкенда. Использование TensorRT-оптимизированных моделей в Triton дает наибольший прирост производительности на GPU NVIDIA.
8. Как мониторить производительность Triton?
Triton предоставляет метрики в формате Prometheus, которые можно собирать и визуализировать с помощью Prometheus и Grafana. Ключевые метрики включают утилизацию GPU, использование памяти GPU, задержку запросов, время в очереди батчинга, количество запросов и ошибки. Для более глубокого мониторинга GPU можно использовать NVIDIA DCGM Exporter.
9. Могу ли я развернуть несколько моделей на одном GPU с Triton?
Да, Triton поддерживает мультимодельный инференс. Вы можете загрузить несколько моделей на один Triton-сервер, и он будет эффективно распределять ресурсы GPU между ними. Это особенно полезно для небольших моделей или для ансамблей моделей, позволяя максимизировать утилизацию GPU.
10. Какие типичные ошибки следует избегать при использовании Triton?
Наиболее распространенные ошибки включают: игнорирование оптимизации моделей (квантизация, TensorRT), неправильную настройку динамического батчинга (что приводит к низкой утилизации или высокой задержке), отсутствие адекватного мониторинга, неправильное управление памятью GPU (OOM-ошибки) и недооценку сложности развертывания в Kubernetes без должной подготовки.
11. Как Triton обрабатывает запросы к stateful моделям (например, LLM с историей)?
Triton предоставляет специальный планировщик sequence_batching для stateful моделей. Он позволяет группировать запросы, принадлежащие к одной логической последовательности (например, диалогу), и отправлять их на инференс вместе с предыдущим состоянием модели. Это обеспечивает корректную работу с контекстом и позволяет применять динамический батчинг даже для последовательных запросов.
12. Можно ли использовать Triton на CPU?
Да, Triton поддерживает CPU-инференс. Хотя его основное преимущество раскрывается на GPU, вы можете использовать Triton для обслуживания моделей на CPU, особенно если у вас нет доступа к GPU или для менее требовательных задач. Для CPU-инференса Triton также предлагает бэкенды для ONNX Runtime, OpenVINO и других фреймворков, оптимизированных для CPU.
Заключение
В мире 2026 года, где AI/ML становится повсеместным, способность эффективно развертывать модели на GPU является ключевым конкурентным преимуществом. NVIDIA Triton Inference Server зарекомендовал себя как мощный и гибкий инструмент, способный обеспечить беспрецедентную производительность, низкую задержку и высокую пропускную способность, максимизируя при этом утилизацию дорогих GPU-ресурсов.
Мы рассмотрели, что успех в оптимизации инференса зависит не только от выбора самого сервера, но и от целого комплекса факторов: от правильного подбора GPU (таких как NVIDIA Blackwell B200) и агрессивной оптимизации моделей (квантизация, TensorRT), до продуманной конфигурации Triton, интеграции с Kubernetes и постоянного мониторинга. Игнорирование любого из этих аспектов может привести к значительным перерасходам и неспособности соответствовать требованиям бизнеса.
Использование Triton Inference Server в сочетании с лучшими практиками, такими как контейнеризация, оркестрация с Kubernetes (KServe/Seldon Core) и комплексный мониторинг, позволяет строить надежные, масштабируемые и экономически эффективные MLOps-пайплайны. Это дает возможность не просто развертывать AI-модели, но и делать это с максимальной отдачей, обеспечивая при этом высочайшее качество обслуживания для конечных пользователей.
Следующие шаги для читателя:
- Начните с малого: Запустите Triton в Docker с одной из ваших моделей, используя базовую конфигурацию.
- Оптимизируйте модель: Попробуйте квантовать свою модель и скомпилировать ее в TensorRT (если используете GPU NVIDIA).
- Экспериментируйте с батчингом: Измените параметры динамического батчинга и
instance_group, чтобы увидеть, как это влияет на производительность.
- Настройте мониторинг: Разверните Prometheus и Grafana для сбора метрик Triton, чтобы визуализировать и анализировать производительность.
- Изучите Kubernetes: Если вы еще не используете Kubernetes, начните изучать его основы, а затем переходите к KServe или Seldon Core для более сложного управления MLOps.
- Профилируйте: Используйте Nsight Systems, чтобы глубоко понять узкие места вашей модели и инфраструктуры.
Путь к высокопроизводительному AI/ML инференсу требует постоянного обучения, экспериментов и итераций. Но инвестиции в эти знания и инструменты окупятся сторицей, обеспечивая вашим AI-продуктам конкурентное преимущество в быстро меняющемся мире 2026 года.